Zakon prosjeka jednostavnim rječnikom. Prosječne vrijednosti. Slabi zakon velikih brojeva
Riječi o velikim brojevima odnose se na broj testova – razmatra se veliki broj vrijednosti slučajne varijable ili kumulativno djelovanje velikog broja slučajnih varijabli. Bit ovog zakona je sljedeća: iako je nemoguće predvidjeti koju će vrijednost jedna slučajna varijabla poprimiti u jednom eksperimentu, međutim, ukupni rezultat djelovanja velikog broja neovisnih slučajnih varijabli gubi svoj slučajni karakter i može predvidjeti gotovo pouzdano (tj. s velikom vjerojatnošću). Na primjer, nemoguće je predvidjeti na koju će stranu pasti novčić. Međutim, ako bacite 2 tone kovanica, tada se s velikom sigurnošću može tvrditi da je težina kovanica koje su pale s grbom prema gore 1 tona.
Prije svega, takozvana Chebyshevljeva nejednakost odnosi se na zakon velikih brojeva, koji u zasebnom testu procjenjuje vjerojatnost da će slučajna varijabla prihvatiti vrijednost koja od prosječne vrijednosti odstupa ne više od zadane vrijednosti.
Čebiševljeva nejednakost. Neka x je proizvoljna slučajna varijabla, a=M(X) , a D(x) je njegova disperzija. Zatim
Primjer. Nazivna (tj. potrebna) vrijednost promjera rukavca obrađenog na stroju je 5 mm, a odstupanja više nema 0.01 (ovo je tolerancija točnosti stroja). Procijenite vjerojatnost da će u proizvodnji jedne čahure odstupanje njenog promjera od nominalnog biti manje od 0,5 mm .
Riješenje. Neka r.v. x- promjer proizvedene čahure. Prema uvjetu, njegovo matematičko očekivanje je jednako nazivnom promjeru (ako nema sustavnog kvara u postavljanju stroja): a=M(X)=5 , i varijanca D(X)≤0,01. Primjenom Čebiševljeve nejednakosti za ε = 0,5, dobivamo:
Dakle, vjerojatnost takvog odstupanja je prilično velika, pa stoga možemo zaključiti da je u slučaju jednokratne proizvodnje dijela gotovo sigurno da odstupanje promjera od nominalnog neće prijeći 0,5 mm .
Uglavnom, standardna devijacija σ karakterizira prosjek odstupanje slučajne varijable od njenog središta (tj. od njenog matematičkog očekivanja). Jer to prosjek odstupanje, tada su tijekom ispitivanja moguća velika odstupanja (naglasak na o). Koliko su velika odstupanja praktično moguća? Kada smo proučavali normalno raspodijeljene slučajne varijable, izveli smo pravilo "tri sigme": normalno raspodijeljena slučajna varijabla x u jednom testu praktički ne odstupa od svog prosjeka dalje od 3σ, gdje σ= σ(X) je standardna devijacija r.v. x. Takvo smo pravilo izveli iz činjenice da smo dobili nejednakost
 .
.
Procijenimo sada vjerojatnost za proizvoljan nasumična varijabla x prihvatiti vrijednost koja se razlikuje od srednje vrijednosti za najviše tri puta standardnu devijaciju. Primjenom Čebiševljeve nejednakosti za ε = 3σ a s obzirom na to D(X)=σ 2 , dobivamo:
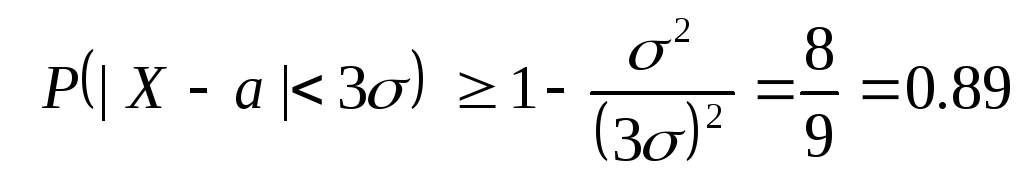 .
.
Na ovaj način, općenito možemo procijeniti vjerojatnost da slučajna varijabla odstupa od svoje srednje vrijednosti za najviše tri standardne devijacije brojem 0.89 , dok se za normalnu distribuciju može jamčiti s vjerojatnošću 0.997 .
Čebiševljeva nejednakost može se generalizirati na sustav nezavisnih identično raspodijeljenih slučajnih varijabli.
Generalizirana Čebiševljeva nejednakost. Ako su nezavisne slučajne varijable x 1 , X 2 , … , X n M(x ja )= a i disperzije D(x ja )= D, onda
Na n=1 ova nejednakost prelazi u gore formuliranu Čebiševljevu nejednakost.
Čebiševljeva nejednakost, koja ima samostalno značenje za rješavanje odgovarajućih problema, koristi se za dokaz tzv. Čebiševljevog teorema. Prvo opisujemo bit ovog teorema, a zatim dajemo njegovu formalnu formulaciju.
Neka x 1
, X 2
, … , X n– veliki broj neovisnih slučajnih varijabli s matematičkim očekivanjima M(X 1
)=a 1
, … , M(X n )=a n. Iako svaki od njih, kao rezultat eksperimenta, može poprimiti vrijednost daleko od svog prosjeka (tj. matematičkog očekivanja), međutim, slučajna varijabla  , jednako njihovoj aritmetičkoj sredini, s velikom će vjerojatnošću poprimiti vrijednost blizu fiksnog broja
, jednako njihovoj aritmetičkoj sredini, s velikom će vjerojatnošću poprimiti vrijednost blizu fiksnog broja  (ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka kao rezultat testa budu nezavisne slučajne varijable x 1
, X 2
, … , X n(ima ih puno!) uzeli vrijednosti prema tome x 1
, X 2
, … , X n odnosno. Zatim, ako se te vrijednosti same po sebi mogu pokazati daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost
(ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka kao rezultat testa budu nezavisne slučajne varijable x 1
, X 2
, … , X n(ima ih puno!) uzeli vrijednosti prema tome x 1
, X 2
, … , X n odnosno. Zatim, ako se te vrijednosti same po sebi mogu pokazati daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost  vjerojatno će biti blizu
vjerojatno će biti blizu  . Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti s velikom točnošću. To se može objasniti činjenicom da slučajna odstupanja vrijednosti x ja iz a ja mogu biti različitih predznaka, pa se stoga ukupno ta odstupanja s velikom vjerojatnošću kompenziraju.
. Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti s velikom točnošću. To se može objasniti činjenicom da slučajna odstupanja vrijednosti x ja iz a ja mogu biti različitih predznaka, pa se stoga ukupno ta odstupanja s velikom vjerojatnošću kompenziraju.
Terema Chebysheva (zakon velikih brojeva u obliku Čebiševa). Neka x 1 , X 2 , … , X n … je niz u parovima neovisnih slučajnih varijabli čije su varijance ograničene na isti broj. Tada, koliko god mali broj ε uzeli, vjerojatnost nejednakosti
bit će proizvoljno blizu jedinici ako je broj n slučajne varijable uzeti dovoljno velike. Formalno, to znači da pod uvjetima iz teorema
Ova vrsta konvergencije naziva se konvergencija u vjerojatnosti i označava se sa:
Dakle, Chebyshevljev teorem kaže da ako postoji dovoljno velik broj neovisnih slučajnih varijabli, tada će njihova aritmetička sredina u jednom testu gotovo sigurno imati vrijednost blizu sredine njihovih matematičkih očekivanja.
Najčešće se Čebiševljev teorem primjenjuje u situaciji kada slučajne varijable x 1 , X 2 , … , X n … imaju istu distribuciju (tj. isti zakon distribucije ili istu gustoću vjerojatnosti). Zapravo, ovo je samo veliki broj instanci iste slučajne varijable.
Posljedica(općene Čebiševljeve nejednakosti). Ako su nezavisne slučajne varijable x 1 , X 2 , … , X n … imaju istu distribuciju s matematičkim očekivanjima M(x ja )= a i disperzije D(x ja )= D, onda
 , tj.
, tj.  .
.
Dokaz slijedi iz generalizirane Chebyshevljeve nejednakosti prelaskom na limes kao n→∞ .
Još jednom napominjemo da gore napisane jednakosti ne jamče da je vrijednost količine  nastoji a na n→∞. Ova je vrijednost još uvijek slučajna varijabla, a njezine pojedinačne vrijednosti mogu biti prilično udaljene a. Ali vjerojatnost takvog (daleko od toga a) vrijednosti s povećanjem n teži 0.
nastoji a na n→∞. Ova je vrijednost još uvijek slučajna varijabla, a njezine pojedinačne vrijednosti mogu biti prilično udaljene a. Ali vjerojatnost takvog (daleko od toga a) vrijednosti s povećanjem n teži 0.
Komentar. Zaključak korolara očito vrijedi iu općenitijem slučaju kada su nezavisne slučajne varijable x 1 , X 2 , … , X n … imaju različitu distribuciju, ali ista matematička očekivanja (jednaka a) i varijance ograničene u agregatu. To omogućuje predviđanje točnosti mjerenja određene količine, čak i ako se ta mjerenja provode različitim instrumentima.
Razmotrimo detaljnije primjenu ovog korolara na mjerenje količina. Iskoristimo neki uređaj n mjerenja iste količine, čija je prava vrijednost a a mi ne znamo. Rezultati takvih mjerenja x 1
, X 2
, … , X n mogu značajno razlikovati jedan od drugog (i od stvarne vrijednosti a) zbog različitih slučajnih čimbenika (padovi tlaka, temperature, slučajne vibracije itd.). Razmotrimo r.v. x- očitanje instrumenta za pojedinačno mjerenje veličine, kao i skupa r.v. x 1
, X 2
, … , X n- očitanje instrumenta pri prvom, drugom, ..., zadnjem mjerenju. Dakle, svaka od količina x 1
, X 2
, … , X n
samo je jedan od primjera r.v. x, te stoga svi imaju istu distribuciju kao i r.v. x. Budući da su rezultati mjerenja neovisni jedni o drugima, r.v. x 1
, X 2
, … , X n može se smatrati neovisnim. Ako uređaj ne daje sustavnu pogrešku (na primjer, nula nije "oborena" na skali, opruga nije rastegnuta itd.), tada možemo pretpostaviti da je matematičko očekivanje M(X) = a, i stoga M(X 1
) = ... = M(X n ) = a. Dakle, uvjeti gornjeg korolara su zadovoljeni, i stoga, kao približna vrijednost količine a možemo uzeti "implementaciju" slučajne varijable  u našem eksperimentu (koji se sastoji od niza n mjerenja), tj.
u našem eksperimentu (koji se sastoji od niza n mjerenja), tj.
 .
.
S velikim brojem mjerenja praktički je pouzdan dobra točnost izračuna pomoću ove formule. To je obrazloženje praktičnog načela da se kod velikog broja mjerenja njihova aritmetička sredina praktički ne razlikuje mnogo od stvarne vrijednosti mjerene veličine.
"Selektivna" metoda, koja se široko koristi u matematičkoj statistici, temelji se na zakonu velikih brojeva, koji omogućuje dobivanje objektivnih karakteristika s prihvatljivom točnošću iz relativno malog uzorka vrijednosti slučajne varijable. Ali o tome će biti riječi u sljedećem odjeljku.
Primjer. Na mjernom uređaju koji ne čini sustavna izobličenja mjeri se određena veličina a jednom (primljena vrijednost x 1
), a zatim još 99 puta (dobivene vrijednosti x 2
, … , X 100
). Za pravu vrijednost mjerenja a prvo uzeti rezultat prvog mjerenja  , a zatim aritmetička sredina svih mjerenja
, a zatim aritmetička sredina svih mjerenja  . Točnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (jer disperzija D=σ
2
također ne prelazi 1). Za svaku od metoda mjerenja procijenite vjerojatnost da pogreška mjerenja ne prelazi 2.
. Točnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (jer disperzija D=σ
2
također ne prelazi 1). Za svaku od metoda mjerenja procijenite vjerojatnost da pogreška mjerenja ne prelazi 2.
Riješenje. Neka r.v. x- očitavanje instrumenta za jedno mjerenje. Zatim po stanju M(X)=a. Da bismo odgovorili na postavljena pitanja, primjenjujemo generaliziranu Čebiševljevu nejednakost

za ε =2
prvo za n=1
a zatim za n=100
. U prvom slučaju dobivamo  , au drugom. Dakle, drugi slučaj praktički jamči zadanu točnost mjerenja, dok prvi ostavlja ozbiljne dvojbe u tom smislu.
, au drugom. Dakle, drugi slučaj praktički jamči zadanu točnost mjerenja, dok prvi ostavlja ozbiljne dvojbe u tom smislu.
Primijenimo gornje izjave na slučajne varijable koje se pojavljuju u Bernoullijevoj shemi. Prisjetimo se suštine ove sheme. Neka se proizvodi n neovisni testovi, u svakom od njih neki događaj ALI mogu se pojaviti s istom vjerojatnošću R, a q=1–r(što znači, ovo je vjerojatnost suprotnog događaja - ne pojavljivanja događaja ALI) . Idemo potrošiti neki broj n takvih testova. Razmotrite slučajne varijable: x 1 – broj pojavljivanja događaja ALI u 1 test, ..., x n– broj pojavljivanja događaja ALI u n th test. Svi uvedeni r.v. može poprimiti vrijednosti 0 ili 1 (događaj ALI može se pojaviti u testu ili ne) i vrijednost 1 uvjetno prihvaćen u svakom ispitivanju s vjerojatnošću str(vjerojatnost nastanka događaja ALI u svakom testu) i vrijednost 0 s vjerojatnošću q= 1 – str. Stoga ove količine imaju iste zakone raspodjele:
|
x 1 | ||
|
x n | ||
Stoga su prosječne vrijednosti ovih veličina i njihove disperzije također iste: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= str ; D(x 1 )=(0 2 ∙ q+1 2 ∙ str)− str 2 = str∙(1− str)= str ∙ q, …, D(x n )= str ∙ q . Zamjenom ovih vrijednosti u generaliziranu Chebyshevljevu nejednakost, dobivamo
 .
.
Jasno je da je r.v. x=x 1 +…+H n je broj pojavljivanja događaja ALI u svemu n suđenja (kako kažu - "broj uspjeha" u n testovi). Neka uđe n ispitni događaj ALI pojavio u k od njih. Tada se prethodna nejednakost može napisati kao
 .
.
Ali veličina  , jednak omjeru broja pojavljivanja događaja ALI u n neovisna ispitivanja, na ukupan broj ispitivanja, prethodno nazvana relativna stopa događaja ALI u n testovi. Dakle, postoji nejednakost
, jednak omjeru broja pojavljivanja događaja ALI u n neovisna ispitivanja, na ukupan broj ispitivanja, prethodno nazvana relativna stopa događaja ALI u n testovi. Dakle, postoji nejednakost
 .
.
Prelazeći sada do granice na n→∞, dobivamo  , tj.
, tj.  (prema vjerojatnosti). Ovo je sadržaj zakona velikih brojeva u obliku Bernoullija. Iz ovoga slijedi da za dovoljno velik broj pokusa n proizvoljno mala odstupanja relativne frekvencije
(prema vjerojatnosti). Ovo je sadržaj zakona velikih brojeva u obliku Bernoullija. Iz ovoga slijedi da za dovoljno velik broj pokusa n proizvoljno mala odstupanja relativne frekvencije  događaja od njegove vjerojatnosti R gotovo su sigurni događaji, a velika odstupanja gotovo nemoguća. Rezultirajući zaključak o takvoj stabilnosti relativnih frekvencija (koju smo prethodno nazivali eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerojatnosti događaja kao broja oko kojeg fluktuira relativna učestalost događaja.
događaja od njegove vjerojatnosti R gotovo su sigurni događaji, a velika odstupanja gotovo nemoguća. Rezultirajući zaključak o takvoj stabilnosti relativnih frekvencija (koju smo prethodno nazivali eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerojatnosti događaja kao broja oko kojeg fluktuira relativna učestalost događaja.
S obzirom na to da izraz str∙
q=
str∙(1−
str)=
str−
str 2
ne prelazi interval promjene  (to je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti
(to je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti  lako to dobiti
lako to dobiti
 ,
,
koji se koristi u rješavanju odgovarajućih problema (jedan od njih će biti dan u nastavku).
Primjer. Novčić je bačen 1000 puta. Procijenite vjerojatnost da će odstupanje relativne učestalosti pojavljivanja grba od njegove vjerojatnosti biti manje od 0,1.
Riješenje. Primjenom nejednakosti  na str=
q=1/2
,
n=1000
,
ε=0,1, dobivamo .
na str=
q=1/2
,
n=1000
,
ε=0,1, dobivamo .
Primjer. Ocijenite vjerojatnost da, pod uvjetima iz prethodnog primjera, broj k odbačenih grbova bit će u rasponu od 400 prije 600 .
Riješenje. Stanje 400<
k<600
znači da 400/1000<
k/
n<600/1000
, tj. 0.4<
W n (A)<0.6
ili  . Kao što smo upravo vidjeli iz prethodnog primjera, vjerojatnost takvog događaja je najmanje 0.975
.
. Kao što smo upravo vidjeli iz prethodnog primjera, vjerojatnost takvog događaja je najmanje 0.975
.
Primjer. Za izračunavanje vjerojatnosti nekog događaja ALI Provedeno je 1000 pokusa u kojima je događaj ALI pojavio 300 puta. Procijenite vjerojatnost da se relativna frekvencija (jednaka 300/1000=0,3) razlikuje od prave vjerojatnosti R ne više od 0,1.
Riješenje. Primjenom gornje nejednakosti  za n=1000, ε=0,1 , dobivamo .
za n=1000, ε=0,1 , dobivamo .
Zakon velikih brojeva
Zakon velikih brojeva u teoriji vjerojatnosti navodi da je empirijska sredina (aritmetička sredina) dovoljno velikog konačnog uzorka iz fiksne distribucije blizu teorijske sredine (očekivanja) ove distribucije. Ovisno o vrsti konvergencije, postoji slabi zakon velikih brojeva, kada dolazi do konvergencije u vjerojatnosti, i jaki zakon velikih brojeva, kada se događa konvergencija gotovo posvuda.
Uvijek će postojati toliki broj pokušaja da će se, s bilo kojom unaprijed određenom vjerojatnošću, relativna učestalost pojavljivanja nekog događaja proizvoljno malo razlikovati od njegove vjerojatnosti.
Općenito značenje zakona velikih brojeva je da zajedničko djelovanje velikog broja slučajnih faktora dovodi do rezultata koji je gotovo neovisan o slučaju.
Na ovom se svojstvu temelje metode za procjenu vjerojatnosti na temelju analize konačnog uzorka. Dobar primjer je predviđanje izbornih rezultata na temelju ankete na uzorku birača.
Slabi zakon velikih brojeva
Neka postoji beskonačan niz (uzastopno nabrajanje) identično distribuiranih i nekoreliranih slučajnih varijabli, definiranih na istom prostoru vjerojatnosti. Odnosno, njihova kovarijanca. Neka . Označimo uzorak srednje vrijednosti prvih članova:
Snažan zakon velikih brojeva
Neka postoji beskonačan niz neovisnih identično distribuiranih slučajnih varijabli, definiranih na istom prostoru vjerojatnosti. Neka . Označimo uzorak srednje vrijednosti prvih članova:
.Onda gotovo sigurno.
vidi također
Književnost
- Shiryaev A. N. Vjerojatnost, - M .: Znanost. 1989. godine.
- Čistjakov V.P. Tečaj teorije vjerojatnosti, - M., 1982.
Zaklada Wikimedia. 2010. godine.
- Kinematografija Rusije
- Gromeka, Mihail Stepanovič
Pogledajte što je "Zakon velikih brojeva" u drugim rječnicima:
ZAKON VELIKIH BROJEVA- (zakon velikih brojeva) U slučaju kada je ponašanje pojedinih članova populacije vrlo distinktivno, ponašanje grupe je u prosjeku predvidljivije od ponašanja bilo kojeg njenog člana. Trend u kojim grupama ... ... Ekonomski rječnik
ZAKON VELIKIH BROJEVA- vidi ZAKON O VELIKIM BROJEVIMA. Antinazi. Enciklopedija sociologije, 2009 ... Enciklopedija sociologije
Zakon velikih brojeva- načelo prema kojem se kvantitativni obrasci svojstveni masovnim društvenim pojavama najjasnije očituju s dovoljno velikim brojem opažanja. Pojedinačni fenomeni su podložniji učincima slučajnih i ... ... Rječnik poslovnih pojmova
ZAKON VELIKIH BROJEVA- tvrdi da će se s vjerojatnošću bliskom jedinici aritmetička sredina velikog broja slučajnih varijabli približno istog reda malo razlikovati od konstante jednake aritmetičkoj sredini matematičkih očekivanja tih varijabli. Razlika…… Geološka enciklopedija
zakon velikih brojeva- — [Ya.N. Luginsky, M.S. Fezi Zhilinskaya, Yu.S. Kabirov. English Russian Dictionary of Electrical Engineering and Power Industry, Moskva, 1999] Teme elektrotehnike, osnovni koncepti EN zakon prosječnezakon velikih brojeva ... Tehnički prevoditeljski priručnik
zakon velikih brojeva- didžiųjų skaičių dėsnis statusas T sritis fizika atitikmenys: engl. zakon velikih brojeva vok. Gesetz der großen Zahlen, n rus. zakon velikih brojeva, m pranc. loi des grands nombres, f … Fizikos terminų žodynas
ZAKON VELIKIH BROJEVA- opće načelo, zbog kojeg kombinirano djelovanje slučajnih čimbenika dovodi, pod određenim vrlo općim uvjetima, do rezultata koji je gotovo neovisan o slučaju. Konvergencija učestalosti pojavljivanja slučajnog događaja s njegovom vjerojatnošću s povećanjem broja ... ... Ruska sociološka enciklopedija
Zakon velikih brojeva- zakon koji tvrdi da kumulativno djelovanje velikog broja slučajnih faktora dovodi, pod određenim vrlo općim uvjetima, do rezultata gotovo neovisnog o slučaju ... Sociologija: rječnik
ZAKON VELIKIH BROJEVA- statistički zakon koji izražava odnos statističkih pokazatelja (parametara) uzorka i opće populacije. Stvarne vrijednosti statističkih pokazatelja dobivenih iz određenog uzorka uvijek se razlikuju od tzv. teoretski ...... Sociologija: Enciklopedija
ZAKON VELIKIH BROJEVA- načelo da se učestalost financijskih gubitaka određene vrste može predvidjeti s velikom točnošću kada postoji veliki broj gubitaka slične vrste ... Enciklopedijski rječnik ekonomije i prava
knjige
- Set stolova. Matematika. Teorija vjerojatnosti i matematička statistika. 6 tablica + metodologija, . Tablice su tiskane na debelom poligrafskom kartonu dimenzija 680 x 980 mm. Pribor uključuje brošuru s metodološkim preporukama za nastavnike. Edukativni album od 6 listova. Slučajno...
Koja je tajna uspješnih prodavača? Ako promatrate najbolje prodavače bilo koje tvrtke, primijetit ćete da imaju jednu zajedničku stvar. Svatko od njih susreće se s više ljudi i održava više prezentacija od manje uspješnih prodavača. Ti ljudi razumiju da je prodaja igra brojki, i što više ljudi govore o svojim proizvodima ili uslugama, to više poslova sklapaju, to je sve. Oni razumiju da ako komuniciraju ne samo s onim malobrojnim koji će im sigurno reći da, nego i s onima čiji interes za njihovu prosidbu nije tako velik, tada će im zakon prosjeka ići u prilog.
Vaša će zarada ovisiti o broju prodaja, ali će u isto vrijeme biti izravno proporcionalna broju prezentacija koje napravite. Jednom kada shvatite i počnete primjenjivati zakon prosjeka, tjeskoba povezana s pokretanjem novog posla ili radom u novom području počet će se smanjivati. Kao rezultat toga, počet će rasti osjećaj kontrole i povjerenje u njihovu sposobnost zarade. Ako samo pravite prezentacije i pritom usavršavate svoje vještine, bit će dogovora.
Umjesto da razmišljate o broju dogovora, razmislite o broju prezentacija. Nema smisla probuditi se ujutro ili doći navečer kući i početi se pitati tko će kupiti vaš proizvod. Umjesto toga, najbolje je planirati svaki dan koliko poziva trebate obaviti. I onda, bez obzira na sve - obavite sve te pozive! Ovaj pristup će vam olakšati posao - jer je to jednostavan i specifičan cilj. Ako znate da pred sobom imate vrlo konkretan i ostvariv cilj, lakše ćete ostvariti planirani broj poziva. Ako tijekom ovog procesa nekoliko puta čujete "da", tim bolje!
A ako "ne", tada ćete navečer osjećati da ste pošteno učinili sve što ste mogli i neće vas mučiti misli o tome koliko ste novca zaradili ili koliko ste partnera stekli u danu.
Recimo da u vašoj tvrtki ili tvrtki prosječni prodavač zaključi jedan posao svake četiri prezentacije. Sada zamislite da izvlačite karte iz špila. Svaka karta od tri boje - pik, karo i tref - predstavlja prezentaciju u kojoj profesionalno predstavljate proizvod, uslugu ili priliku. Radiš to najbolje što možeš, ali još uvijek ne sklapaš posao. A svaka srčana karta je ponuda koja vam omogućuje da dobijete novac ili steknete novog suputnika.
Ne biste li u takvoj situaciji htjeli izvući što više karata iz špila? Pretpostavimo da vam je ponuđeno da izvučete onoliko karata koliko želite, a plaća vam ili predlaže novog suputnika svaki put kada izvučete karticu srca. Počet ćete s entuzijazmom izvlačiti karte, jedva primjećujući koje je boje karta upravo izvučena.
Znate da postoji trinaest srca u špilu od pedeset i dvije karte. I u dva špila - dvadeset i šest srčanih karata, i tako dalje. Hoćete li biti razočarani izvlačenjem pik, karo ili tref? Naravno da ne! Samo ćete misliti da vas svaki takav "promašaj" približava - čemu? Na kartu srca!
Ali znate što? Već ste dobili ovu ponudu. U jedinstvenoj ste poziciji da zaradite onoliko koliko želite i izvučete onoliko srčanih karata koliko želite u svom životu. A ako samo savjesno "vučete karte", usavršavate svoje vještine i izdržite malo pik, karo i tref, tada ćete postati izvrstan prodavač i uspjeti.
Jedna od stvari zbog koje je prodaja tako zabavna jest to što se svaki put kad promiješate špil, karte se izmiješaju drugačije. Ponekad sva srca završe na početku špila, a nakon uspješnog niza (kada nam se već čini da nikad nećemo izgubiti!) čeka nas dugačak niz karata različite boje. A drugi put, da dođeš do prvog herca, moraš proći beskonačan broj pikova, trefa i tambura. A ponekad karte različitih boja ispadaju strogo redom. Ali u svakom slučaju, u svakom špilu od pedeset i dvije karte, nekim redoslijedom, uvijek se nalazi trinaest srca. Samo izvlačite karte dok ih ne pronađete.
Od: Leylya,
Zakon velikih brojeva u teoriji vjerojatnosti navodi da je empirijska sredina (aritmetička sredina) dovoljno velikog konačnog uzorka iz fiksne distribucije blizu teorijske sredine (očekivanja) ove distribucije. Ovisno o vrsti konvergencije, razlikuju se slabi zakon velikih brojeva, kada postoji konvergencija u vjerojatnosti, i jaki zakon velikih brojeva, kada se odvija konvergencija gotovo svugdje.
Uvijek postoji konačan broj pokušaja za koje je, s bilo kojom danom vjerojatnošću, manje od 1 relativna učestalost pojavljivanja nekog događaja proizvoljno će se malo razlikovati od njegove vjerojatnosti.
Općenito značenje zakona velikih brojeva: zajedničko djelovanje velikog broja istovjetnih i neovisnih slučajnih faktora dovodi do rezultata koji, u granicama, ne ovisi o slučaju.
Na ovom se svojstvu temelje metode za procjenu vjerojatnosti na temelju analize konačnog uzorka. Dobar primjer je predviđanje izbornih rezultata na temelju ankete na uzorku birača.
Enciklopedijski YouTube
1 / 5
✪ Zakon velikih brojeva
✪ 07 - Teorija vjerojatnosti. Zakon velikih brojeva
✪ 42 Zakon velikih brojeva
✪ 1 - Čebiševljev zakon velikih brojeva
✪ 11. razred, lekcija 25, Gaussova krivulja. Zakon velikih brojeva
titlovi
Pogledajmo zakon velikih brojeva, koji je možda najintuitivniji zakon u matematici i teoriji vjerojatnosti. A budući da se odnosi na toliko mnogo stvari, ponekad se koristi i pogrešno shvaća. Dopustite mi da prvo dam definiciju za točnost, a onda ćemo govoriti o intuiciji. Uzmimo slučajnu varijablu, recimo X. Recimo da znamo njezino matematičko očekivanje ili srednju populaciju. Zakon velikih brojeva jednostavno kaže da ako uzmemo primjer n-tog broja opažanja slučajne varijable i uprosječimo broj svih tih opažanja... Uzmimo varijablu. Nazovimo ga X s indeksom n i crticom na vrhu. Ovo je aritmetička sredina n-tog broja opažanja naše slučajne varijable. Evo moje prve opservacije. Napravim eksperiment jednom i napravim ovo opažanje, onda to ponovim i napravim ovo opažanje, ponovim to i dobijem ovo. Izvodim ovaj eksperiment n puta i zatim dijelim s brojem svojih opažanja. Ovdje je moj uzorak srednje vrijednosti. Ovdje je prosjek svih opažanja koja sam napravio. Zakon velikih brojeva govori nam da će se moja sredina uzorka približiti sredini slučajne varijable. Ili također mogu napisati da će se moja sredina uzorka približiti srednjoj vrijednosti populacije za n-ti broj koji ide u beskonačnost. Neću praviti jasnu razliku između "aproksimacije" i "konvergencije", ali nadam se da intuitivno razumijete da ako ovdje uzmem prilično velik uzorak, tada ću dobiti očekivanu vrijednost za populaciju u cjelini. Mislim da većina vas intuitivno razumije da ako napravim dovoljno testova s velikim uzorkom primjera, na kraju će mi testovi dati vrijednosti koje očekujem, uzimajući u obzir matematičko očekivanje, vjerojatnost i sve to. Ali mislim da je često nejasno zašto se to događa. I prije nego počnem objašnjavati zašto je to tako, dat ću vam konkretan primjer. Zakon velikih brojeva nam govori da... Recimo da imamo slučajnu varijablu X. Ona je jednaka broju glava u 100 bacanja ispravnog novčića. Prije svega, znamo matematičko očekivanje ove slučajne varijable. Ovo je broj bacanja novčića ili pokušaja pomnožen izgledima da bilo koji pokušaj uspije. Dakle, jednako je 50. Odnosno, zakon velikih brojeva kaže da ako uzmemo uzorak, ili ako izračunam prosjek ovih pokušaja, dobijem. .. Prvi put kad radim test, bacim novčić 100 puta, ili uzmem kutiju sa stotinu novčića, protresem je i onda prebrojim koliko glava dobijem i dobijem, recimo, broj 55. Ovo će biti X1. Zatim ponovno protresem kutiju i dobijem broj 65. Onda opet - i dobijem 45. I to učinim n puta, a zatim to podijelim s brojem pokušaja. Zakon velikih brojeva govori nam da će ovaj prosjek (prosjek svih mojih opažanja) težiti 50 dok će n težiti beskonačnosti. Sada bih želio govoriti malo o tome zašto se to događa. Mnogi smatraju da ako mi nakon 100 pokušaja rezultat bude iznad prosjeka, onda bih po zakonima vjerojatnosti trebao imati više ili manje glava kako bih, da tako kažem, nadoknadio razliku. Ovo nije baš ono što će se dogoditi. Ovo se često naziva "zabluda kockara". Dopustite mi da vam pokažem razliku. Poslužit ću se sljedećim primjerom. Dopustite mi da nacrtam grafikon. Promijenimo boju. Ovo je n, moja x-os je n. Ovo je broj testova koje ću provesti. A moja y-os će biti srednja vrijednost uzorka. Znamo da je srednja vrijednost ove proizvoljne varijable 50. Daj da nacrtam ovo. Ovo je 50. Vratimo se našem primjeru. Ako je n... Tijekom prvog testa dobio sam 55, što je moj prosjek. Imam samo jednu točku unosa podataka. Zatim, nakon dva pokušaja, dobijem 65. Dakle, moj prosjek bi bio 65+55 podijeljeno s 2. To je 60. I moj prosjek je malo porastao. Tada sam dobio 45, što mi je opet snizilo aritmetičku sredinu. Neću ucrtati 45 na grafikonu. Sada moram izračunati prosjek. Čemu je jednako 45+65? Dopustite mi da izračunam ovu vrijednost da predstavim točku. To je 165 podijeljeno s 3. To je 53. Ne, 55. Dakle, prosjek opet pada na 55. Možemo nastaviti s ovim testovima. Nakon što smo napravili tri pokušaja i došli do ovog prosjeka, mnogi ljudi misle da će bogovi vjerojatnosti učiniti tako da dobijemo manje glava u budućnosti, da će sljedećih nekoliko pokušaja biti niži kako bi se smanjio prosjek. Ali nije uvijek tako. U budućnosti, vjerojatnost uvijek ostaje ista. Vjerojatnost da ću bacati glave uvijek će biti 50%. Nije da u početku dobijem određeni broj glava, više nego što očekujem, a onda bi odjednom trebali ispasti repovi. Ovo je "zabluda igrača". Ako dobijete nesrazmjeran broj glava, to ne znači da će vam u nekom trenutku početi padati nesrazmjeran broj repova. Ovo nije posve točno. Zakon velikih brojeva nam govori da to nije važno. Recimo, nakon određenog konačnog broja pokušaja, vaš prosjek... Vjerojatnost za to je prilično mala, ali, ipak... Recimo da vaš prosjek dosegne ovu granicu - 70. Mislite: "Vau, prošli smo daleko iznad očekivanja." Ali zakon velikih brojeva kaže da nije važno koliko testova provodimo. Pred nama je još beskonačan broj kušnji. Matematičko očekivanje ovog beskonačnog broja pokušaja, posebno u ovakvoj situaciji, bit će sljedeće. Kada dođete do konačnog broja koji izražava neku veliku vrijednost, beskonačni broj koji mu konvergira opet će dovesti do očekivane vrijednosti. Ovo je, naravno, vrlo slobodno tumačenje, ali to je ono što nam govori zakon velikih brojeva. To je važno. Ne kaže nam da će se, ako dobijemo puno glava, vjerojatnost dobivanja repova nekako povećati da bi se to kompenziralo. Ovaj zakon nam govori da nije važno kakav je rezultat s konačnim brojem pokušaja sve dok još uvijek imate beskonačan broj pokušaja ispred sebe. A ako ih napravite dovoljno, opet ćete se vratiti očekivanjima. Ovo je važna točka. Razmisli o tome. Ali to se ne koristi svakodnevno u praksi s lutrijom i kockarnicama, iako je poznato da ako napravite dovoljno testova... Možemo čak i izračunati... koja je vjerojatnost da ćemo ozbiljno odstupiti od norme? Ali kockarnice i lutrije rade svakodnevno po principu da ako uzmete dovoljno ljudi, naravno, u kratkom vremenu, s malim uzorkom, onda će nekoliko ljudi pogoditi jackpot. Ali dugoročno gledano, kasino će uvijek imati koristi od parametara igara koje vas poziva da igrate. Ovo je važno načelo vjerojatnosti koje je intuitivno. Iako ponekad, kada vam se to formalno objasni slučajnim varijablama, sve to izgleda pomalo zbunjujuće. Sve što ovaj zakon kaže je da što je više uzoraka, to će više aritmetička sredina tih uzoraka konvergirati prema pravoj sredini. I da budemo precizniji, aritmetička sredina vašeg uzorka će konvergirati s matematičkim očekivanjem slučajne varijable. To je sve. Vidimo se u sljedećem videu!
Slabi zakon velikih brojeva
Slabi zakon velikih brojeva naziva se i Bernoullijev teorem, po Jacobu Bernoulliju, koji ga je dokazao 1713.
Neka postoji beskonačan niz (uzastopno nabrajanje) identično raspoređenih i nekoreliranih slučajnih varijabli. Odnosno, njihova kovarijanca c o v (X i , X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). Neka . Označimo uzorkom srednje vrijednosti prvog n (\displaystyle n)članovi:
.
Zatim X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
Odnosno za svaku pozitivu ε (\displaystyle \varepsilon )
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Snažan zakon velikih brojeva
Neka postoji beskonačan niz nezavisnih identično distribuiranih slučajnih varijabli ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty )) definiran na jednom prostoru vjerojatnosti (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F)),\mathbb (P))). Neka E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N) ). Označimo sa X¯n (\displaystyle (\bar(X))_(n)) uzorak srednje vrijednosti prvog n (\displaystyle n)članovi:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i),\;n\in \mathbb (N) ).Zatim X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu ) skoro uvijek.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ desno)=1.) .Kao i svaki drugi matematički zakon, zakon velikih brojeva može se primijeniti na stvarni svijet samo pod poznatim pretpostavkama, koje se mogu zadovoljiti samo s određenim stupnjem točnosti. Tako se, primjerice, uvjeti uzastopnih testova često ne mogu održavati neograničeno dugo i s apsolutnom točnošću. Osim toga, zakon velikih brojeva samo govori o nevjerojatnost značajno odstupanje srednje vrijednosti od matematičkog očekivanja.
Prosječna vrijednost je najopćenitiji pokazatelj u statistici. To je zbog činjenice da se može koristiti za karakterizaciju stanovništva prema kvantitativno varirajućem atributu. Na primjer, za usporedbu plaća radnika dvaju poduzeća ne mogu se uzeti plaće dvaju konkretnih radnika, budući da one djeluju kao promjenjivi pokazatelj. Također, ne može se uzeti ukupan iznos isplaćenih plaća u poduzećima, jer on ovisi o broju zaposlenih. Podijelimo li ukupni iznos plaća svakog poduzeća s brojem zaposlenih, možemo ih usporediti i utvrditi koje poduzeće ima višu prosječnu plaću.
Drugim riječima, plaće proučavane populacije radnika dobivaju generaliziranu karakteristiku u prosječnoj vrijednosti. Izražava ono opće i tipično što je svojstveno ukupnosti radnika u odnosu na osobinu koja se proučava. U ovoj vrijednosti pokazuje opću mjeru ovog atributa, koja ima različitu vrijednost za jedinice populacije.
Određivanje prosječne vrijednosti. Prosječna vrijednost u statistici je generalizirana karakteristika skupa sličnih pojava prema nekom kvantitativno varirajućem atributu. Prosječna vrijednost pokazuje razinu ovog obilježja u odnosu na populacijsku jedinicu. Uz pomoć prosječne vrijednosti moguće je međusobno usporediti različite agregate prema različitim karakteristikama (dohodak po glavi stanovnika, prinosi usjeva, troškovi proizvodnje u različitim poduzećima).
Prosječna vrijednost uvijek generalizira kvantitativnu varijaciju značajke kojom karakteriziramo populaciju koju proučavamo, a koja je jednako svojstvena svim jedinicama populacije. To znači da iza svake prosječne vrijednosti uvijek stoji niz distribucije jedinica populacije prema nekom varirajućem atributu, tj. varijacijske serije. U tom smislu, prosječna vrijednost se bitno razlikuje od relativnih vrijednosti, a posebno od pokazatelja intenziteta. Pokazatelj intenziteta je omjer obujma dvaju različitih agregata (npr. proizvodnja BDP-a po stanovniku), dok prosječni generalizira karakteristike elemenata agregata prema jednom od obilježja (npr. prosjek plaća radnika).
Srednja vrijednost i zakon velikih brojeva. U promjeni prosječnih pokazatelja očituje se opći trend, pod čijim utjecajem se formira proces razvoja fenomena u cjelini, dok se u pojedinačnim pojedinačnim slučajevima taj trend ne mora očitovati jasno. Važno je da se prosjeci temelje na masovnoj generalizaciji činjenica. Samo pod tim uvjetom oni će otkriti opći trend koji je u pozadini procesa u cjelini.
Bit zakona velikih brojeva i njegovo značenje za prosjeke, kako se broj promatranja povećava, sve potpunije poništava odstupanja nastala slučajnim uzrocima. To jest, zakon velikih brojeva stvara uvjete da se tipična razina varirajućeg atributa pojavi u prosječnoj vrijednosti pod određenim uvjetima mjesta i vremena. Vrijednost ove razine određena je suštinom ovog fenomena.
Vrste prosjeka. Srednje vrijednosti koje se koriste u statistici pripadaju klasi srednjih snaga, čija je opća formula sljedeća:
Gdje je x srednja vrijednost snage;
X - mijenjanje vrijednosti atributa (opcije)
- opcija broja
Eksponent srednje vrijednosti;
Znak zbrajanja.
Za različite vrijednosti eksponenta srednje vrijednosti dobivaju se različite vrste srednje vrijednosti:
Aritmetička sredina;
Glavni trg;
Prosječna kubna;
Prosječni harmonik;
Geometrijska sredina.
Različite vrste srednjih vrijednosti imaju različita značenja kada se koriste iste izvorne statistike. Istovremeno, što je veći eksponent prosjeka, to je njegova vrijednost veća.
U statistici se točna karakterizacija stanovništva u svakom pojedinom slučaju daje samo potpuno određenom vrstom prosječnih vrijednosti. Za određivanje ove vrste prosječne vrijednosti koristi se kriterij koji određuje svojstva prosjeka: prosječna vrijednost će tek tada biti prava generalizirajuća karakteristika populacije prema varirajućem atributu, kada, kada se sve varijante zamijene prosjekom vrijednost, ukupni volumen varirajućeg atributa ostaje nepromijenjen. To jest, točna vrsta prosjeka određena je načinom na koji se formira ukupni volumen varijabilnog obilježja. Dakle, aritmetička sredina se koristi kada se volumen varijabilnog obilježja formira kao zbroj pojedinačnih opcija, srednji kvadrat - kada se volumen varijabilnog obilježja formira kao zbroj kvadrata, harmonijska sredina - kao zbroj recipročne vrijednosti pojedinih opcija, geometrijska sredina - kao produkt pojedinačnih opcija. Osim prosječnih vrijednosti u statistici
Korištena su deskriptivna obilježja distribucije varijabilnog obilježja (strukturni prosjeci), mod (najčešća varijanta) i medijan (srednja varijanta).



