Prawo średnich w prostych słowach. Wartości średnie. Słabe prawo wielkich liczb
Słowa o dużych liczbach odnoszą się do liczby testów - uwzględniana jest duża liczba wartości zmiennej losowej lub skumulowane działanie dużej liczby zmiennych losowych. Istota tego prawa jest następująca: chociaż nie można przewidzieć, jaką wartość przybierze pojedyncza zmienna losowa w pojedynczym eksperymencie, to jednak łączny wynik działania dużej liczby niezależnych zmiennych losowych traci swój losowy charakter i może być przewidywane prawie wiarygodnie (tj. z dużym prawdopodobieństwem). Na przykład nie można przewidzieć, na którą stronę spadnie moneta. Jeśli jednak podrzucisz 2 tony monet, to z dużą pewnością można argumentować, że waga monet, które spadły z herbem do góry, wynosi 1 tonę.
Przede wszystkim tzw. nierówność Czebyszewa odwołuje się do prawa wielkich liczb, które w osobnym teście szacuje prawdopodobieństwo przyjęcia przez zmienną losową wartości odbiegającej od wartości średniej nie więcej niż o określoną wartość.
Nierówność Czebyszewa. Wynajmować X jest dowolną zmienną losową, a=M(X) , a D(X) jest jego rozproszenie. Następnie
Przykład. Nominalna (tj. wymagana) wartość średnicy tulei obrabianej na maszynie wynosi 5mm, a wariancja już nie istnieje 0.01 (jest to tolerancja dokładności maszyny). Oszacuj prawdopodobieństwo, że podczas produkcji jednej tulei odchylenie jej średnicy od nominalnej będzie mniejsze niż 0,5 mm .
Rozwiązanie. Niech r.v. X- średnica produkowanej tulei. Według warunku jego matematyczne oczekiwanie jest równe średnicy nominalnej (jeśli nie ma systematycznych błędów podczas ustawiania maszyny): a=M(X)=5 , a wariancja D(X) ≤0,01. Zastosowanie nierówności Czebyszewa do: ε = 0,5 otrzymujemy:
Zatem prawdopodobieństwo wystąpienia takiego odchylenia jest dość duże, a zatem możemy wnioskować, że w przypadku pojedynczej produkcji części jest prawie pewne, że odchylenie średnicy od nominalnej nie przekroczy 0,5 mm .
Zasadniczo odchylenie standardowe σ charakteryzuje przeciętny odchylenie zmiennej losowej od jej środka (tj. od jej matematycznego oczekiwania). Ponieważ to przeciętny odchylenia, to podczas testowania możliwe są duże odchylenia (nacisk na o). Jak duże odchylenia są praktycznie możliwe? Badając zmienne losowe o rozkładzie normalnym, wyprowadziliśmy zasadę „trzech sigma”: zmienna losowa o rozkładzie normalnym X w jednym teście praktycznie nie odbiega od średniej dalej niż 3σ, gdzie σ= σ(X) jest odchyleniem standardowym r.v. X. Taką regułę wywnioskowaliśmy z faktu, że uzyskaliśmy nierówność
 .
.
Oszacujmy teraz prawdopodobieństwo dla arbitralny zmienna losowa X zaakceptować wartość, która różni się od średniej o nie więcej niż trzykrotność odchylenia standardowego. Zastosowanie nierówności Czebyszewa do: ε = 3σ i biorąc to pod uwagę D(X)=σ 2 otrzymujemy:
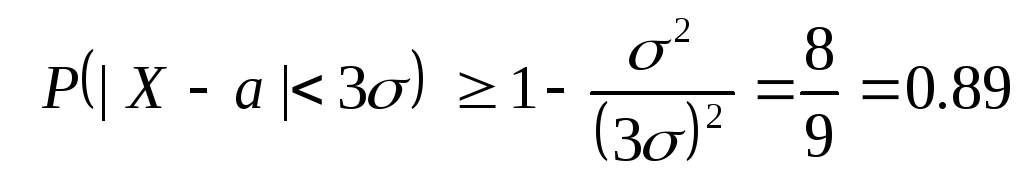 .
.
W ten sposób, ogólnie możemy oszacować prawdopodobieństwo odchylenia zmiennej losowej od jej średniej o nie więcej niż trzy odchylenia standardowe o liczbę 0.89 , podczas gdy dla rozkładu normalnego można to zagwarantować z prawdopodobieństwem 0.997 .
Nierówność Czebyszewa można uogólnić do układu niezależnych zmiennych losowych o identycznym rozkładzie.
Uogólniona nierówność Czebyszewa. Jeśli niezależne zmienne losowe X 1 , X 2 , … , X n M(X i )= a i dyspersje D(X i )= D, następnie
Na n=1 ta nierówność przechodzi w sformułowaną powyżej nierówność Czebyszewa.
Nierówność Czebyszewa, mająca niezależne znaczenie dla rozwiązania odpowiednich problemów, służy do udowodnienia tak zwanego twierdzenia Czebyszewa. Najpierw opisujemy istotę tego twierdzenia, a następnie podajemy jego formalne sformułowanie.
Wynajmować X 1
, X 2
, … , X n– duża liczba niezależnych zmiennych losowych z matematycznymi oczekiwaniami M(X 1
)=a 1
, … , M(X n )=a n. Chociaż każdy z nich w wyniku eksperymentu może przyjąć wartość daleką od swojej średniej (tj. matematycznego oczekiwania), to jednak zmienna losowa  , równe ich średniej arytmetycznej, z dużym prawdopodobieństwem przyjmie wartość zbliżoną do ustalonej liczby
, równe ich średniej arytmetycznej, z dużym prawdopodobieństwem przyjmie wartość zbliżoną do ustalonej liczby  (jest to średnia wszystkich oczekiwań matematycznych). Oznacza to, co następuje. Niech w wyniku testu niezależne zmienne losowe X 1
, X 2
, … , X n(jest ich dużo!) odpowiednio przyjęły wartości X 1
, X 2
, … , X n odpowiednio. Następnie, jeśli same te wartości mogą okazać się dalekie od średnich wartości odpowiednich zmiennych losowych, ich średnia wartość
(jest to średnia wszystkich oczekiwań matematycznych). Oznacza to, co następuje. Niech w wyniku testu niezależne zmienne losowe X 1
, X 2
, … , X n(jest ich dużo!) odpowiednio przyjęły wartości X 1
, X 2
, … , X n odpowiednio. Następnie, jeśli same te wartości mogą okazać się dalekie od średnich wartości odpowiednich zmiennych losowych, ich średnia wartość  prawdopodobnie będzie blisko
prawdopodobnie będzie blisko  . Tym samym średnia arytmetyczna dużej liczby zmiennych losowych traci już swój losowy charakter i może być przewidywana z dużą dokładnością. Można to wyjaśnić faktem, że losowe odchylenia wartości X i z a i mogą mieć różne znaki, dlatego w sumie odchylenia te są kompensowane z dużym prawdopodobieństwem.
. Tym samym średnia arytmetyczna dużej liczby zmiennych losowych traci już swój losowy charakter i może być przewidywana z dużą dokładnością. Można to wyjaśnić faktem, że losowe odchylenia wartości X i z a i mogą mieć różne znaki, dlatego w sumie odchylenia te są kompensowane z dużym prawdopodobieństwem.
Terema Czebyszewa (prawo wielkich liczb w postaci Czebyszewa). Wynajmować X 1 , X 2 , … , X n … jest ciągiem parami niezależnych zmiennych losowych, których wariancje są ograniczone do tej samej liczby. Wtedy, bez względu na to, jak małą liczbę ε przyjmiemy, prawdopodobieństwo nierówności
będzie arbitralnie bliski jedności, jeśli liczba n zmienne losowe, aby były wystarczająco duże. Formalnie oznacza to, że w warunkach twierdzenia
Ten rodzaj zbieżności nazywa się zbieżnością prawdopodobieństwa i jest oznaczany przez:
Tak więc twierdzenie Czebyszewa mówi, że jeśli istnieje wystarczająco duża liczba niezależnych zmiennych losowych, to ich średnia arytmetyczna w jednym teście prawie na pewno przyjmie wartość zbliżoną do średniej ich matematycznych oczekiwań.
Najczęściej twierdzenie Czebyszewa stosuje się w sytuacji, gdy zmienne losowe X 1 , X 2 , … , X n … mają ten sam rozkład (tj. to samo prawo rozkładu lub tę samą gęstość prawdopodobieństwa). W rzeczywistości jest to po prostu duża liczba wystąpień tej samej zmiennej losowej.
Konsekwencja(o uogólnionej nierówności Czebyszewa). Jeśli niezależne zmienne losowe X 1 , X 2 , … , X n … mają taki sam rozkład z matematycznymi oczekiwaniami M(X i )= a i dyspersje D(X i )= D, następnie
 , tj.
, tj.  .
.
Dowód wynika z uogólnionej nierówności Czebyszewa, przechodząc do granicy jako n→∞ .
Zauważamy raz jeszcze, że powyższe równości nie gwarantują, że wartość ilości  ma zwyczaj a w n→∞. Wartość ta jest nadal zmienną losową, a jej poszczególne wartości mogą być dość dalekie od a. Ale prawdopodobieństwo takiego (daleko od a) wartości ze wzrostem n dąży do 0.
ma zwyczaj a w n→∞. Wartość ta jest nadal zmienną losową, a jej poszczególne wartości mogą być dość dalekie od a. Ale prawdopodobieństwo takiego (daleko od a) wartości ze wzrostem n dąży do 0.
Komentarz. Wniosek z tego wniosku jest oczywiście słuszny również w bardziej ogólnym przypadku, gdy niezależne zmienne losowe X 1 , X 2 , … , X n … mają inny rozkład, ale te same oczekiwania matematyczne (równe a) oraz wariancje ograniczone łącznie. Umożliwia to przewidywanie dokładności pomiaru określonej wielkości, nawet jeśli pomiary te są wykonywane różnymi przyrządami.
Rozważmy bardziej szczegółowo zastosowanie tego następstwa do pomiaru wielkości. Użyjmy jakiegoś urządzenia n pomiary tej samej wielkości, których rzeczywista wartość to a i nie wiemy. Wyniki takich pomiarów X 1
, X 2
, … , X n mogą znacznie różnić się od siebie (i od prawdziwej wartości) a) z powodu różnych czynników losowych (spadki ciśnienia, temperatury, przypadkowe drgania itp.). Rozważ r.v. X- odczyt przyrządu dla pojedynczego pomiaru wielkości oraz zestawu r.v. X 1
, X 2
, … , X n- odczyt przyrządu przy pierwszym, drugim, ... ostatnim pomiarze. Tak więc każda z ilości X 1
, X 2
, … , X n
istnieje tylko jeden z przykładów r.v. X, a zatem wszystkie mają taki sam rozkład jak r.v. X. Ponieważ wyniki pomiarów są od siebie niezależne, r.v. X 1
, X 2
, … , X n można uznać za niezależne. Jeśli urządzenie nie daje błędu systematycznego (na przykład zero nie jest „powalone” na skali, sprężyna nie jest rozciągnięta itp.), wówczas możemy założyć, że matematyczne oczekiwanie M(X) = a, i dlatego M(X 1
) = ... = M(X n ) = a. Spełnione są zatem warunki z powyższego wniosku, a więc jako przybliżona wartość wielkości a możemy wziąć „implementację” zmiennej losowej  w naszym eksperymencie (składający się z serii n pomiary), tj.
w naszym eksperymencie (składający się z serii n pomiary), tj.
 .
.
Przy dużej liczbie pomiarów jest praktycznie niezawodny dobra dokładność obliczenia przy użyciu tego wzoru. Jest to uzasadnienie praktycznej zasady, że przy dużej liczbie pomiarów ich średnia arytmetyczna praktycznie nie różni się zbytnio od rzeczywistej wartości mierzonej wielkości.
Metoda „selektywna”, szeroko stosowana w statystyce matematycznej, opiera się na prawie dużych liczb, co pozwala uzyskać jej obiektywną charakterystykę z akceptowalną dokładnością ze stosunkowo niewielkiej próby wartości zmiennej losowej. Ale zostanie to omówione w następnej sekcji.
Przykład. Na urządzeniu pomiarowym, które nie powoduje systematycznych zniekształceń, mierzy się pewną ilość a raz (otrzymana wartość X 1
), a następnie kolejne 99 razy (uzyskane wartości X 2
, … , X 100
). Dla prawdziwej wartości pomiaru a najpierw weź wynik pierwszego pomiaru  , a następnie średnia arytmetyczna wszystkich pomiarów
, a następnie średnia arytmetyczna wszystkich pomiarów  . Dokładność pomiaru urządzenia jest taka, że odchylenie standardowe pomiaru σ nie jest większe niż 1 (ponieważ dyspersja D=σ
2
również nie przekracza 1). Dla każdej z metod pomiarowych oszacuj prawdopodobieństwo, że błąd pomiaru nie przekracza 2.
. Dokładność pomiaru urządzenia jest taka, że odchylenie standardowe pomiaru σ nie jest większe niż 1 (ponieważ dyspersja D=σ
2
również nie przekracza 1). Dla każdej z metod pomiarowych oszacuj prawdopodobieństwo, że błąd pomiaru nie przekracza 2.
Rozwiązanie. Niech r.v. X- odczyt przyrządu dla pojedynczego pomiaru. Następnie według warunku M(X)=a. Aby odpowiedzieć na postawione pytania, stosujemy uogólnioną nierówność Czebyszewa

dla ε =2
pierwszy za n=1
a potem dla n=100
. W pierwszym przypadku otrzymujemy  , aw drugim. Zatem drugi przypadek praktycznie gwarantuje daną dokładność pomiaru, podczas gdy pierwszy pozostawia w tym sensie poważne wątpliwości.
, aw drugim. Zatem drugi przypadek praktycznie gwarantuje daną dokładność pomiaru, podczas gdy pierwszy pozostawia w tym sensie poważne wątpliwości.
Zastosujmy powyższe stwierdzenia do zmiennych losowych, które powstają w schemacie Bernoulliego. Przypomnijmy istotę tego schematu. Niech się wyprodukuje n niezależne testy, w każdym z nich jakieś zdarzenie ALE może pojawić się z tym samym prawdopodobieństwem R, a q=1–r(co oznacza, że jest to prawdopodobieństwo odwrotnego zdarzenia - nie wystąpienia zdarzenia) ALE) . Wydajmy trochę n takie testy. Rozważ zmienne losowe: X 1 – liczba wystąpień zdarzenia ALE w 1 test, ..., X n– liczba wystąpień zdarzenia ALE w n test. Wszystkie wprowadzone r.v. może przyjmować wartości 0 lub 1 (wydarzenie ALE może pojawić się w teście lub nie), a wartość 1 warunkowo akceptowany w każdej próbie z prawdopodobieństwem p(prawdopodobieństwo wystąpienia zdarzenia) ALE w każdym teście) oraz wartość 0 z prawdopodobieństwem q= 1 – p. Dlatego te ilości mają te same prawa dystrybucji:
|
X 1 | ||
|
X n | ||
Dlatego średnie wartości tych wielkości i ich rozrzuty są również takie same: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= p ; D(X 1 )=(0 2 ∙ q+1 2 ∙ p)− p 2 = p∙(1− p)= p ∙ q, … , D(X n )= p ∙ q . Podstawiając te wartości do uogólnionej nierówności Czebyszewa, otrzymujemy
 .
.
Oczywiste jest, że r.v. X=X 1 +…+X n to liczba wystąpień zdarzenia ALE we wszystkim n prób (jak to mówią - "liczba sukcesów" w n testy). Wpuść n zdarzenie testowe ALE pojawił się w k z nich. Wtedy poprzednią nierówność można zapisać jako
 .
.
Ale wielkość  , równy stosunkowi liczby wystąpień zdarzenia ALE w n niezależnych prób, do całkowitej liczby prób, wcześniej nazywanej względną częstością zdarzeń ALE w n testy. Dlatego istnieje nierówność
, równy stosunkowi liczby wystąpień zdarzenia ALE w n niezależnych prób, do całkowitej liczby prób, wcześniej nazywanej względną częstością zdarzeń ALE w n testy. Dlatego istnieje nierówność
 .
.
Przechodzimy teraz do limitu o n→∞, otrzymujemy  , tj.
, tj.  (według prawdopodobieństwa). To jest treść prawa wielkich liczb w postaci Bernoulliego. Wynika z tego, że dla wystarczająco dużej liczby prób n dowolnie małe odchylenia częstotliwości względnej
(według prawdopodobieństwa). To jest treść prawa wielkich liczb w postaci Bernoulliego. Wynika z tego, że dla wystarczająco dużej liczby prób n dowolnie małe odchylenia częstotliwości względnej  zdarzenia z jego prawdopodobieństwa R są prawie pewne zdarzenia, a duże odchylenia są prawie niemożliwe. Wynikający z tego wniosek o takiej stabilności względnych częstotliwości (którą wcześniej nazywaliśmy eksperymentalny fakt) uzasadnia wprowadzoną wcześniej statystyczną definicję prawdopodobieństwa zdarzenia jako liczbę, wokół której oscyluje względna częstotliwość zdarzenia.
zdarzenia z jego prawdopodobieństwa R są prawie pewne zdarzenia, a duże odchylenia są prawie niemożliwe. Wynikający z tego wniosek o takiej stabilności względnych częstotliwości (którą wcześniej nazywaliśmy eksperymentalny fakt) uzasadnia wprowadzoną wcześniej statystyczną definicję prawdopodobieństwa zdarzenia jako liczbę, wokół której oscyluje względna częstotliwość zdarzenia.
Biorąc pod uwagę, że wyrażenie p∙
q=
p∙(1−
p)=
p−
p 2
nie przekracza interwału wymiany  (łatwo to zweryfikować, znajdując minimum tej funkcji na tym odcinku), z powyższej nierówności
(łatwo to zweryfikować, znajdując minimum tej funkcji na tym odcinku), z powyższej nierówności  łatwo to zdobyć
łatwo to zdobyć
 ,
,
który służy do rozwiązywania odpowiednich problemów (jeden z nich zostanie podany poniżej).
Przykład. Moneta została przerzucona 1000 razy. Oszacuj prawdopodobieństwo, że odchylenie względnej częstotliwości występowania herbu od jego prawdopodobieństwa będzie mniejsze niż 0,1.
Rozwiązanie. Stosowanie nierówności  w p=
q=1/2
,
n=1000
,
ε=0,1, otrzymujemy .
w p=
q=1/2
,
n=1000
,
ε=0,1, otrzymujemy .
Przykład. Oszacuj prawdopodobieństwo, że w warunkach poprzedniego przykładu liczba k zrzuconych herbów będzie w zakresie 400 zanim 600 .
Rozwiązanie. Stan 400<
k<600
oznacza, że 400/1000<
k/
n<600/1000
, tj. 0.4<
W n (A)<0.6
lub  . Jak właśnie widzieliśmy z poprzedniego przykładu, prawdopodobieństwo takiego zdarzenia wynosi co najmniej 0.975
.
. Jak właśnie widzieliśmy z poprzedniego przykładu, prawdopodobieństwo takiego zdarzenia wynosi co najmniej 0.975
.
Przykład. Aby obliczyć prawdopodobieństwo jakiegoś zdarzenia ALE Przeprowadzono 1000 eksperymentów, w których zdarzenie ALE pojawił się 300 razy. Oszacuj prawdopodobieństwo, że częstotliwość względna (równa 300/1000=0,3) różni się od prawdopodobieństwa rzeczywistego R nie dalej niż 0,1 .
Rozwiązanie. Stosując powyższą nierówność  dla n=1000, ε=0,1 otrzymujemy .
dla n=1000, ε=0,1 otrzymujemy .
Prawo wielkich liczb
Prawo wielkich liczb w teorii prawdopodobieństwa stwierdza się, że średnia empiryczna (średnia arytmetyczna) wystarczająco dużej próbki skończonej z ustalonego rozkładu jest zbliżona do średniej teoretycznej (oczekiwanej) tego rozkładu. W zależności od rodzaju zbieżności istnieje słabe prawo dużych liczb, gdy zachodzi zbieżność prawdopodobieństwa, oraz silne prawo dużych liczb, gdy zbieżność zachodzi prawie wszędzie.
Zawsze będzie taka liczba prób, że przy dowolnym z góry określonym prawdopodobieństwie względna częstość występowania jakiegoś zdarzenia będzie się arbitralnie mało różniła od jego prawdopodobieństwa.
Ogólne znaczenie prawa wielkich liczb polega na tym, że wspólne działanie dużej liczby czynników losowych prowadzi do wyniku prawie niezależnego od przypadku.
Na tej właściwości opierają się metody szacowania prawdopodobieństwa oparte na analizie próbki skończonej. Dobrym przykładem jest przewidywanie wyników wyborów na podstawie badania próby wyborców.
Słabe prawo wielkich liczb
Niech będzie nieskończony ciąg (kolejne wyliczanie) identycznie rozłożonych i nieskorelowanych zmiennych losowych, określonych na tej samej przestrzeni prawdopodobieństwa . To znaczy ich kowariancja. Wynajmować . Oznaczmy średnią z próby pierwszych wyrazów:
Silne prawo wielkich liczb
Niech będzie nieskończony ciąg niezależnych, identycznie rozłożonych zmiennych losowych, określonych w tej samej przestrzeni prawdopodobieństwa. Wynajmować . Oznaczmy średnią z próby pierwszych wyrazów:
.Wtedy prawie na pewno.
Zobacz też
Literatura
- Shiryaev A. N. Prawdopodobieństwo, - M.: Nauka. 1989.
- Chistyakov V.P. Kurs teorii prawdopodobieństwa, - M., 1982.
Fundacja Wikimedia. 2010 .
- Kino Rosji
- Gromeka, Michaił Stiepanowicz
Zobacz, czym jest „Prawo wielkich liczb” w innych słownikach:
PRAWO WIELKICH LICZB- (prawo wielkich liczb) W przypadku, gdy zachowanie poszczególnych członków populacji jest wysoce charakterystyczne, zachowanie grupy jest średnio bardziej przewidywalne niż zachowanie któregokolwiek z jej członków. Trend, w którym grupy ... ... Słownik ekonomiczny
PRAWO WIELKICH LICZB- patrz PRAWO O DUŻYCH LICZBACH. Antynazi. Encyklopedia Socjologii, 2009 ... Encyklopedia Socjologii
Prawo wielkich liczb- zasada, zgodnie z którą wzorce ilościowe nieodłącznie związane z masowymi zjawiskami społecznymi przejawiają się najdobitniej przy wystarczająco dużej liczbie obserwacji. Pojedyncze zjawiska są bardziej podatne na skutki losowe i ... ... Słowniczek pojęć biznesowych
PRAWO WIELKICH LICZB- twierdzi, że z prawdopodobieństwem bliskim jedności średnia arytmetyczna dużej liczby zmiennych losowych mniej więcej tego samego rzędu będzie niewiele różniła się od stałej równej średniej arytmetycznej oczekiwań matematycznych tych zmiennych. Różnica… … Encyklopedia geologiczna
prawo wielkich liczb- — [Ja.N. Ługiński, M.S. Fezi Zhilinskaya, Yu.S. Kabirov. Angielsko-rosyjski słownik elektrotechniki i energetyki, Moskwa, 1999] Tematy elektrotechniki, podstawowe pojęcia EN prawo średniej prawa wielkich liczb ... Podręcznik tłumacza technicznego
prawo wielkich liczb- didžiųjų skaičių dėsnis statusas T sritis fizika atitikmenys: engl. prawo wielkich liczb vok. Gesetz der großen Zahlen, n rus. prawo wielkich liczb, m pranc. loi des grands nombres, f … Fizikos terminų žodynas
PRAWO WIELKICH LICZB- ogólna zasada, zgodnie z którą połączone działanie czynników losowych prowadzi w pewnych bardzo ogólnych warunkach do wyniku prawie niezależnego od przypadku. Zbieżność częstości występowania zdarzenia losowego z jego prawdopodobieństwem ze wzrostem liczby ... ... Rosyjska encyklopedia socjologiczna
Prawo wielkich liczb- prawo mówiące, że kumulatywne działanie dużej liczby czynników losowych prowadzi w pewnych bardzo ogólnych warunkach do wyniku prawie niezależnego od przypadku... Socjologia: słownik
PRAWO WIELKICH LICZB- prawo statystyczne wyrażające zależność wskaźników statystycznych (parametrów) próby i populacji ogólnej. Rzeczywiste wartości wskaźników statystycznych uzyskanych z określonej próby zawsze różnią się od tzw. teoretyczne ... ... Socjologia: Encyklopedia
PRAWO WIELKICH LICZB- zasada, że częstość strat finansowych określonego rodzaju można przewidzieć z dużą dokładnością, gdy występuje duża liczba strat podobnego rodzaju... Encyklopedyczny słownik ekonomii i prawa
Książki
- Zestaw stołów. Matematyka. Teoria prawdopodobieństwa i statystyka matematyczna. 6 tabel + metodologia, . Tabele drukowane są na grubej tekturze poligraficznej o wymiarach 680 x 980 mm. Do zestawu dołączona jest broszura z zaleceniami metodycznymi dla nauczycieli. Album edukacyjny 6 arkuszy. Losowy…
Jaki jest sekret odnoszących sukcesy sprzedawców? Jeśli przyjrzysz się najlepszym handlowcom jakiejkolwiek firmy, zauważysz, że łączy ich jedno. Każdy z nich spotyka się z większą liczbą osób i robi więcej prezentacji niż mniej udani sprzedawcy. Ci ludzie rozumieją, że sprzedaż to gra liczb, a im więcej ludzi opowiadają o swoich produktach lub usługach, tym więcej transakcji zawierają, to wszystko. Rozumieją, że jeśli komunikują się nie tylko z tymi nielicznymi, którzy z pewnością powiedzą im tak, ale także z tymi, których zainteresowanie ich propozycją nie jest tak duże, to prawo średnich będzie działać na ich korzyść.
Twoje zarobki będą zależeć od liczby sprzedaży, ale jednocześnie będą wprost proporcjonalne do liczby wykonanych prezentacji. Kiedy zrozumiesz i zaczniesz stosować w praktyce prawo średnich, niepokój związany z rozpoczęciem nowego biznesu lub pracą w nowej dziedzinie zacznie się zmniejszać. A w rezultacie zacznie rosnąć poczucie kontroli i pewność, że potrafią zarabiać. Jeśli po prostu robisz prezentacje i doskonalisz swoje umiejętności w tym procesie, będą oferty.
Zamiast myśleć o liczbie ofert, pomyśl o liczbie prezentacji. Nie ma sensu budzić się rano lub wracać do domu wieczorem i zastanawiać się, kto kupi Twój produkt. Zamiast tego najlepiej zaplanować każdy dzień pod kątem liczby połączeń, które musisz wykonać. A potem, bez względu na wszystko - wykonuj wszystkie te telefony! Takie podejście ułatwi Ci pracę - bo to prosty i konkretny cel. Jeśli wiesz, że masz przed sobą bardzo konkretny i osiągalny cel, łatwiej będzie Ci wykonać zaplanowaną liczbę połączeń. Jeśli podczas tego procesu kilka razy usłyszysz „tak”, tym lepiej!
A jeśli „nie”, to wieczorem poczujesz, że uczciwie zrobiłeś wszystko, co mogłeś, i nie będziesz dręczyć cię myślami o tym, ile zarobiłeś pieniędzy lub ile partnerów pozyskałeś w ciągu dnia.
Załóżmy, że w Twojej firmie lub firmie przeciętny sprzedawca zamyka jedną transakcję na cztery prezentacje. Teraz wyobraź sobie, że dobierasz karty z talii. Każda karta trzech kolorów – pik, karo i trefl – to prezentacja, w której profesjonalnie prezentujesz produkt, usługę lub okazję. Robisz to najlepiej jak potrafisz, ale nadal nie zamykasz transakcji. A każda karta serca to okazja, która pozwala zdobyć pieniądze lub zdobyć nowego towarzysza.
Czy w takiej sytuacji nie chciałbyś dobrać jak największej liczby kart z talii? Załóżmy, że masz dobrać tyle kart, ile chcesz, płacąc ci lub sugerując nowego towarzysza za każdym razem, gdy dobierzesz kartę serca. Zaczniesz entuzjastycznie dobierać karty, ledwo zauważając, w jakim kolorze karta właśnie została wyciągnięta.
Wiesz, że w talii pięćdziesięciu dwóch kart jest trzynaście kier. A w dwóch taliach - dwadzieścia sześć kart kier i tak dalej. Rozczarujesz się losowaniem pik, kar lub trefl? Oczywiście nie! Pomyślisz tylko, że każda taka „chyba” przybliża Cię – do czego? Do karty serc!
Ale wiesz co? Otrzymałeś już tę ofertę. Jesteś w wyjątkowej sytuacji, aby zarobić tyle, ile chcesz i dobrać tyle kart serca, ile chcesz w swoim życiu. A jeśli po prostu sumiennie „dobierzesz karty”, poprawisz swoje umiejętności i zniesiesz trochę łopaty, diamentu i maczugi, staniesz się doskonałym sprzedawcą i odniesiesz sukces.
Jedną z rzeczy, które sprawiają, że sprzedaż jest tak zabawna, jest to, że za każdym razem, gdy tasujesz talię, karty są tasowane w inny sposób. Czasami wszystkie kiery kończą się na początku talii, a po udanej passie (kiedy już wydaje nam się, że nigdy nie przegramy!) czekamy na długi rząd kart w innym kolorze. A innym razem, aby dostać się do pierwszego kiera, trzeba przejść przez nieskończoną ilość pik, maczug i tamburynów. A czasami karty w różnych kolorach wypadają ściśle po kolei. Ale w każdym razie w każdej talii pięćdziesięciu dwóch kart, w jakiejś kolejności, zawsze jest trzynaście kier. Po prostu wyciągaj karty, aż je znajdziesz.
Od: Leylya,
Prawo wielkich liczb w teorii prawdopodobieństwa stwierdza się, że średnia empiryczna (średnia arytmetyczna) wystarczająco dużej próbki skończonej z ustalonego rozkładu jest zbliżona do średniej teoretycznej (oczekiwanej) tego rozkładu. W zależności od typu zbieżności rozróżnia się słabe prawo dużych liczb, gdy zachodzi zbieżność prawdopodobieństwa, oraz silne prawo dużych liczb, gdy zbieżność zachodzi prawie wszędzie.
Zawsze istnieje skończona liczba prób, dla których przy dowolnym prawdopodobieństwie jest mniejsza niż 1 względna częstotliwość występowania jakiegoś zdarzenia będzie arbitralnie mało różniła się od jego prawdopodobieństwa.
Ogólne znaczenie prawa wielkich liczb: wspólne działanie dużej liczby identycznych i niezależnych czynników losowych prowadzi do wyniku, który w granicach nie zależy od przypadku.
Na tej właściwości opierają się metody szacowania prawdopodobieństwa oparte na analizie próbki skończonej. Dobrym przykładem jest przewidywanie wyników wyborów na podstawie badania próby wyborców.
Encyklopedyczny YouTube
1 / 5
✪Prawo wielkich liczb
✪ 07 – Teoria prawdopodobieństwa. Prawo wielkich liczb
✪ 42 Prawo wielkich liczb
✪ 1 - Prawo wielkich liczb Czebyszewa
✪ Klasa 11, lekcja 25, krzywa Gaussa. Prawo wielkich liczb
Napisy na filmie obcojęzycznym
Przyjrzyjmy się prawu wielkich liczb, które jest prawdopodobnie najbardziej intuicyjnym prawem matematyki i teorii prawdopodobieństwa. A ponieważ dotyczy tak wielu rzeczy, jest czasem używany i źle rozumiany. Pozwólcie, że najpierw podam definicję dokładności, a potem porozmawiamy o intuicji. Weźmy zmienną losową, powiedzmy X. Powiedzmy, że znamy jej matematyczne oczekiwanie lub średnią populacji. Prawo wielkich liczb mówi po prostu, że jeśli weźmiemy przykład n-tej liczby obserwacji zmiennej losowej i uśrednimy liczbę wszystkich tych obserwacji... Weźmy zmienną. Nazwijmy to X z indeksem dolnym n i myślnikiem na górze. Jest to średnia arytmetyczna n-tej liczby obserwacji naszej zmiennej losowej. Oto moja pierwsza obserwacja. Robię eksperyment raz i robię tę obserwację, potem robię to ponownie i robię tę obserwację, robię to ponownie i rozumiem. Przeprowadzam ten eksperyment n razy, a następnie dzielę przez liczbę moich obserwacji. Oto moja przykładowa średnia. Oto średnia ze wszystkich moich obserwacji. Prawo wielkich liczb mówi nam, że moja średnia z próby zbliży się do średniej zmiennej losowej. Albo mogę też napisać, że moja średnia z próby zbliży się do średniej populacji dla n-tej liczby idącej do nieskończoności. Nie będę robił wyraźnego rozróżnienia między „przybliżeniem” a „zbieżnością”, ale mam nadzieję, że intuicyjnie rozumiesz, że jeśli wezmę tutaj dość dużą próbę, otrzymam oczekiwaną wartość dla całej populacji. Myślę, że większość z Was intuicyjnie rozumie, że jeśli zrobię wystarczająco dużo testów na dużej próbce przykładów, to w końcu testy dadzą mi wartości, których oczekuję, biorąc pod uwagę oczekiwanie matematyczne, prawdopodobieństwo i tak dalej. Ale myślę, że często nie jest jasne, dlaczego tak się dzieje. A zanim zacznę wyjaśniać, dlaczego tak jest, podam konkretny przykład. Prawo wielkich liczb mówi nam, że... Załóżmy, że mamy zmienną losową X. Jest ona równa liczbie orłów w 100 rzutach prawidłowej monety. Przede wszystkim znamy matematyczne oczekiwanie tej zmiennej losowej. Jest to liczba rzutów monetą lub prób pomnożona przez szanse powodzenia każdej próby. Czyli równa się 50. To znaczy, prawo wielkich liczb mówi, że jeśli weźmiemy próbkę lub jeśli uśrednię te próby, otrzymam. .. Za pierwszym razem, gdy robię test, rzucam monetą 100 razy lub biorę pudełko ze stu monetami, potrząsam nim, a następnie liczę, ile dostanę orłów i dostaję, powiedzmy, liczbę 55. To będzie X1. Potem znowu potrząsam pudełkiem i otrzymuję liczbę 65. Potem znowu - i otrzymuję 45. Robię to n razy, a następnie dzielę przez liczbę prób. Prawo wielkich liczb mówi nam, że ta średnia (średnia wszystkich moich obserwacji) będzie dążyła do 50, podczas gdy n będzie dążyło do nieskończoności. Teraz chciałbym trochę porozmawiać o tym, dlaczego tak się dzieje. Wielu uważa, że jeśli po 100 próbach mój wynik jest powyżej średniej, to zgodnie z prawami prawdopodobieństwa powinienem mieć mniej lub więcej głów, żeby, że tak powiem, wyrównać różnicę. Nie do końca tak się stanie. Często określa się to mianem „błędu hazardzisty”. Pokażę ci różnicę. Posłużę się następującym przykładem. Pozwól, że narysuję wykres. Zmieńmy kolor. To jest n, moja oś x to n. To jest liczba testów, które przeprowadzę. A moja oś Y będzie średnią próbki. Wiemy, że średnia tej arbitralnej zmiennej wynosi 50. Pozwól mi to narysować. To jest 50. Wróćmy do naszego przykładu. Jeśli n to... Podczas mojego pierwszego testu uzyskałem 55, co jest moją średnią. Mam tylko jeden punkt wprowadzania danych. Potem po dwóch próbach uzyskałem 65. Więc moja średnia to 65+55 podzielona przez 2. To jest 60. Moja średnia trochę wzrosła. Potem dostałem 45, co ponownie obniżyło moją średnią arytmetyczną. Nie wykreślę na wykresie 45. Teraz muszę to wszystko uśrednić. Co to jest 45+65? Pozwólcie, że obliczę tę wartość, aby przedstawić punkt. To 165 podzielone przez 3. To 53. Nie, 55. Więc średnia znowu spada do 55. Możemy kontynuować te testy. Po wykonaniu trzech prób i ustaleniu tej średniej wiele osób myśli, że bogowie prawdopodobieństwa sprawią, że w przyszłości będziemy mieli mniej głów, że kilka następnych prób będzie niższych, aby zmniejszyć średnią. Ale nie zawsze tak jest. W przyszłości prawdopodobieństwo zawsze pozostaje takie samo. Prawdopodobieństwo, że rzucę głową, zawsze będzie wynosić 50%. Nie żebym początkowo miał określoną liczbę orłów, więcej niż się spodziewałem, a potem nagle wypadną reszki. To jest „błędem gracza”. Jeśli zdobędziesz nieproporcjonalną liczbę orzełków, nie oznacza to, że w pewnym momencie zaczniesz spadać nieproporcjonalną liczbę orzełków. To nie do końca prawda. Prawo wielkich liczb mówi nam, że to nie ma znaczenia. Powiedzmy, że po pewnej skończonej liczbie prób twoja średnia... Prawdopodobieństwo tego jest dość małe, ale jednak... Powiedzmy, że twoja średnia osiąga ten poziom - 70. Myślisz: „Wow, przeszliśmy daleko poza oczekiwania”. Ale prawo wielkich liczb mówi, że nie ma znaczenia, ile testów przeprowadzimy. Przed nami wciąż nieskończona liczba prób. Matematyczne oczekiwanie tej nieskończonej liczby prób, zwłaszcza w takiej sytuacji, będzie następujące. Kiedy wymyślisz skończoną liczbę, która wyraża jakąś wielką wartość, nieskończona liczba, która zbiega się z nią, ponownie doprowadzi do oczekiwanej wartości. Jest to oczywiście bardzo luźna interpretacja, ale tak mówi nam prawo wielkich liczb. To jest ważne. Nie mówi nam, że jeśli zdobędziemy dużo orłów, to jakoś wzrosną szanse na otrzymanie reszki, aby to zrekompensować. To prawo mówi nam, że nie ma znaczenia, jaki jest wynik przy skończonej liczbie prób, o ile wciąż masz przed sobą nieskończoną liczbę prób. A jeśli zrobisz z nich wystarczająco dużo, znów wrócisz do oczekiwań. To jest ważna kwestia. Pomyśl o tym. Ale nie jest to stosowane na co dzień w loteriach i kasynach, chociaż wiadomo, że jeśli zrobisz wystarczająco dużo testów... Możemy to nawet policzyć... jakie jest prawdopodobieństwo, że poważnie odejdziemy od normy? Ale kasyna i loterie działają na co dzień w oparciu o zasadę, że jeśli weźmiesz wystarczającą ilość osób, oczywiście w krótkim czasie, z małą próbką, to kilka osób trafi w dziesiątkę. Ale w dłuższej perspektywie kasyno zawsze będzie korzystać z parametrów gier, do których Cię zaprasza. Jest to ważna zasada prawdopodobieństwa, która jest intuicyjna. Chociaż czasami, gdy jest to formalnie wyjaśnione zmiennymi losowymi, wszystko to wygląda trochę zagmatwane. Wszystko to mówi, że im więcej jest próbek, tym bardziej średnia arytmetyczna tych próbek będzie zbiegać się do prawdziwej średniej. A dokładniej, średnia arytmetyczna próbki będzie zbieżna z matematycznym oczekiwaniem zmiennej losowej. To wszystko. Do zobaczenia w następnym filmie!
Słabe prawo wielkich liczb
Słabe prawo wielkich liczb jest również nazywane twierdzeniem Bernoulliego, od JacobaBernoulliego, który udowodnił je w 1713 roku.
Niech będzie nieskończony ciąg (kolejne wyliczanie) identycznie rozłożonych i nieskorelowanych zmiennych losowych . To znaczy ich kowariancja c o v (X ja , X j) = 0 , ∀ ja ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\nie =j). Wynajmować . Oznacz jako średnią z próby pierwszego n (\styl wyświetlania n) członkowie:
.
Następnie X ¯ n → P μ (\displaystyle (\bar (X))_(n)\do ^(\!\!\!\!\!\!\mathbb (P) )\mu).
To znaczy dla każdego pozytywu ε (\displaystyle \varepsilon)
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Silne prawo wielkich liczb
Niech będzie nieskończony ciąg niezależnych zmiennych losowych o identycznym rozkładzie ( X ja ) ja = 1 ∞ (\ Displaystyle \ (X_ (i) \) _ (i = 1) ^ (\ infty )) zdefiniowany na jednej przestrzeni prawdopodobieństwa (Ω , F , P) (\displaystyle (\Omega,(\mathcal (F)),\mathbb (P))). Wynajmować mi X ja = μ , ∀ ja ∈ N (\ Displaystyle \ mathbb (E) X_ (i) = \ mu , \; \ forall i \ w \ mathbb (N) ). Oznacz przez X¯n (\displaystyle (\bar(X))_(n))średnia próbka pierwszego n (\styl wyświetlania n) członkowie:
X ¯ n = 1 n ∑ i = 1 n X ja , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\suma \limity_(i= 1)^(n)X_(i),\;n\w \mathbb (N) ).Następnie X ¯ n → μ (\ Displaystyle (\ bar (X)) _ (n) \ do \ mu) prawie zawsze.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\ Displaystyle \ Pr \! \ lewo (\ lim _ (n \ do \ infty ) (\ bar (X)) _ (n) = \ mu \ prawo)=1.) .Jak każde prawo matematyczne, prawo wielkich liczb można zastosować do świata rzeczywistego tylko przy znanych założeniach, które można spełnić tylko z pewnym stopniem dokładności. Na przykład warunki kolejnych testów często nie mogą być utrzymane w nieskończoność iz absolutną dokładnością. Ponadto prawo wielkich liczb mówi tylko o nieprawdopodobieństwo znaczne odchylenie wartości średniej od oczekiwań matematycznych.
Średnia wartość jest najbardziej ogólnym wskaźnikiem w statystyce. Wynika to z faktu, że można go wykorzystać do scharakteryzowania populacji według atrybutu zmiennego ilościowo. Na przykład, aby porównać płace pracowników dwóch przedsiębiorstw, nie można wziąć płac dwóch konkretnych pracowników, ponieważ działa to jako zmienny wskaźnik. Nie można również wziąć całkowitej kwoty wynagrodzeń wypłacanych w przedsiębiorstwach, ponieważ zależy to od liczby pracowników. Jeśli podzielimy łączną kwotę wynagrodzeń każdego przedsiębiorstwa przez liczbę pracowników, możemy je porównać i określić, które przedsiębiorstwo ma wyższą średnią płacę.
Innymi słowy, wynagrodzenia badanej populacji pracowników otrzymują uogólnioną charakterystykę w wartości średniej. Wyraża to, co ogólne i typowe, charakterystyczne dla ogółu pracowników w odniesieniu do badanej cechy. W tej wartości pokazuje ogólną miarę tego atrybutu, która ma inną wartość dla jednostek populacji.
Wyznaczenie wartości średniej. Średnia wartość w statystyce jest uogólnioną charakterystyką zbioru podobnych zjawisk według jakiejś zmiennej ilościowo atrybutu. Średnia wartość pokazuje poziom tej cechy w odniesieniu do jednostki populacji. Za pomocą wartości średniej można porównać ze sobą różne agregaty według różnych cech (dochód per capita, plony, koszty produkcji w różnych przedsiębiorstwach).
Wartość średnia zawsze uogólnia ilościową zmienność cechy, za pomocą której charakteryzujemy badaną populację i która jest jednakowo nieodłączna dla wszystkich jednostek populacji. Oznacza to, że za każdą wartością średnią kryje się zawsze ciąg rozmieszczenia jednostek populacji według jakiegoś zmiennego atrybutu, tj. seria wariacji. Pod tym względem średnia wartość zasadniczo różni się od wartości względnych, a w szczególności od wskaźników intensywności. Wskaźnik intensywności to stosunek wielkości dwóch różnych agregatów (na przykład produkcji PKB na mieszkańca), podczas gdy średnia uogólnia cechy elementów agregatu zgodnie z jedną z cech (na przykład średnia wynagrodzenie pracownika).
Wartość średnia i prawo wielkich liczb. W zmianie wskaźników przeciętnych ujawnia się ogólna tendencja, pod wpływem której kształtuje się proces rozwoju zjawisk jako całości, przy czym w poszczególnych pojedynczych przypadkach tendencja ta może nie ujawnić się wyraźnie. Ważne jest, aby średnie opierały się na masowym uogólnieniu faktów. Tylko pod tym warunkiem ujawnią ogólny trend leżący u podstaw całego procesu.
Istota prawa wielkich liczb i jego znaczenie dla średnich wraz ze wzrostem liczby obserwacji coraz bardziej znosi odchylenia generowane przez przyczyny losowe. Oznacza to, że prawo wielkich liczb stwarza warunki do pojawienia się typowego poziomu zmiennej cechy w średniej wartości w określonych warunkach miejsca i czasu. O wartości tego poziomu decyduje istota tego zjawiska.
Rodzaje średnich. Wartości średnie stosowane w statystyce należą do klasy średnich mocy, których ogólna formuła jest następująca:
Gdzie x jest średnią potęgową;
X - zmiana wartości atrybutu (opcje)
- opcja liczby
Wykładnik średniej;
Znak podsumowujący.
Dla różnych wartości wykładnika średniej otrzymuje się różne typy średniej:
Średnia arytmetyczna;
Średnia kwadratowa;
Średnia sześcienna;
Średnia harmoniczna;
Średnia geometryczna.
Różne rodzaje średnich mają różne znaczenia, gdy używane są te same statystyki źródłowe. Jednocześnie im większy wykładnik średniej, tym wyższa jej wartość.
W statystyce poprawna charakterystyka populacji w każdym indywidualnym przypadku jest podana tylko przez całkowicie określony typ wartości średnich. Do określenia tego typu wartości średniej stosuje się kryterium, które określa właściwości średniej: wartość średnia będzie dopiero wtedy prawdziwą cechą uogólniającą populację według zmieniającego się atrybutu, gdy wszystkie warianty zostaną zastąpione średnią wartość, całkowita objętość zmiennego atrybutu pozostaje niezmieniona. Oznacza to, że prawidłowy typ średniej zależy od tego, jak powstaje całkowita objętość zmiennej cechy. Tak więc średnią arytmetyczną stosuje się, gdy objętość cechy zmiennej tworzy się jako sumę poszczególnych wariantów, średnią kwadratową - gdy objętość cechy zmiennej tworzy się jako sumę kwadratów, średnią harmoniczną - jako sumę wzajemne wartości poszczególnych opcji, średnia geometryczna - jako iloczyn poszczególnych opcji. Oprócz średnich wartości w statystykach
Wykorzystuje się opisową charakterystykę rozkładu cechy zmiennej (średnie strukturalne), mody (wariant najczęściej spotykany) i mediany (wariant środkowy).



