กฎของค่าเฉลี่ยในแง่ง่าย ค่าเฉลี่ย กฎหมายที่อ่อนแอของตัวเลขจำนวนมาก
คำเกี่ยวกับจำนวนมากหมายถึงจำนวนการทดสอบ - พิจารณาค่าจำนวนมากของตัวแปรสุ่มหรือการกระทำสะสมของตัวแปรสุ่มจำนวนมาก สาระสำคัญของกฎหมายนี้มีดังต่อไปนี้: แม้ว่าจะเป็นไปไม่ได้ที่จะคาดการณ์ว่าตัวแปรสุ่มตัวเดียวจะใช้ค่าใดในการทดลองเดียว อย่างไรก็ตาม ผลรวมของการกระทำของตัวแปรสุ่มอิสระจำนวนมากจะสูญเสียลักษณะสุ่มและสามารถ คาดการณ์ได้เกือบน่าเชื่อถือ (เช่น มีความเป็นไปได้สูง) ตัวอย่างเช่น เป็นไปไม่ได้ที่จะทำนายว่าเหรียญจะตกด้านใด อย่างไรก็ตาม หากคุณโยนเหรียญ 2 ตัน ด้วยความมั่นใจอย่างมาก ก็สามารถโต้แย้งได้ว่าน้ำหนักของเหรียญที่ตกลงมาพร้อมแขนเสื้อขึ้นคือ 1 ตัน
ประการแรก ความไม่เท่าเทียมกันที่เรียกว่า Chebyshev หมายถึงกฎของตัวเลขจำนวนมาก ซึ่งประเมินความน่าจะเป็นในการยอมรับค่าโดยตัวแปรสุ่มที่เบี่ยงเบนจากค่าเฉลี่ยไม่เกินค่าที่กำหนดในการทดสอบแยกต่างหาก
ความไม่เท่าเทียมกันของ Chebyshev. อนุญาต Xเป็นตัวแปรสุ่มตามอำเภอใจ a=M(X) , แ ดี(X) คือการกระจายตัวของมัน แล้ว
ตัวอย่าง. ค่าที่ระบุ (เช่น จำเป็น) ของเส้นผ่านศูนย์กลางของปลอกที่ตัดเฉือนบนเครื่องคือ 5mmและความแปรปรวนไม่เกิน 0.01 (นี่คือความทนทานต่อความแม่นยำของเครื่อง) ประมาณความน่าจะเป็นที่ในการผลิตบุชชิ่งหนึ่งส่วนเบี่ยงเบนของเส้นผ่านศูนย์กลางจากค่าเล็กน้อยจะน้อยกว่า 0.5mm .
วิธีการแก้. ให้ r.v. X- เส้นผ่านศูนย์กลางของบุชชิ่งที่ผลิตขึ้น ตามเงื่อนไข การคาดหมายทางคณิตศาสตร์จะเท่ากับเส้นผ่านศูนย์กลางเล็กน้อย (หากไม่มีความล้มเหลวอย่างเป็นระบบในการตั้งค่าเครื่อง): a=M(X)=5 และความแปรปรวน ดี(X) ≤0.01. การใช้ความไม่เท่าเทียมกันของ Chebyshev สำหรับ ε = 0.5, เราได้รับ:
ดังนั้นความน่าจะเป็นของการเบี่ยงเบนดังกล่าวจึงค่อนข้างสูง ดังนั้นเราจึงสรุปได้ว่าในกรณีของการผลิตชิ้นส่วนเดียว ความเบี่ยงเบนของเส้นผ่านศูนย์กลางจากค่าเล็กน้อยจะไม่เกินแน่นอน 0.5mm .
โดยทั่วไป ค่าเบี่ยงเบนมาตรฐาน σ ลักษณะ เฉลี่ยการเบี่ยงเบนของตัวแปรสุ่มจากจุดศูนย์กลาง (เช่น จากการคาดหมายทางคณิตศาสตร์) เพราะมัน เฉลี่ยส่วนเบี่ยงเบนจากนั้นค่าเบี่ยงเบนขนาดใหญ่ (เน้นที่ o) เป็นไปได้ในระหว่างการทดสอบ เป็นไปได้จริงค่าเบี่ยงเบนมากเพียงใด? เมื่อศึกษาตัวแปรสุ่มแบบกระจายปกติ เราได้รับกฎ "สามซิกมา": ตัวแปรสุ่มแบบกระจายปกติ X ในการทดสอบเดียวในทางปฏิบัติไม่เบี่ยงเบนไปจากค่าเฉลี่ยเกินกว่า 3σ, ที่ไหน σ= σ(X)คือค่าเบี่ยงเบนมาตรฐานของ r.v. X. เราอนุมานกฎดังกล่าวได้จากข้อเท็จจริงที่เราได้รับความไม่เท่าเทียมกัน
 .
.
ตอนนี้ให้เราประมาณความน่าจะเป็นของ โดยพลการตัวแปรสุ่ม Xยอมรับค่าที่แตกต่างจากค่าเฉลี่ยไม่เกินสามเท่าของค่าเบี่ยงเบนมาตรฐาน การใช้ความไม่เท่าเทียมกันของ Chebyshev สำหรับ ε = 3σและให้สิ่งนั้น ดี(X)=σ 2 , เราได้รับ:
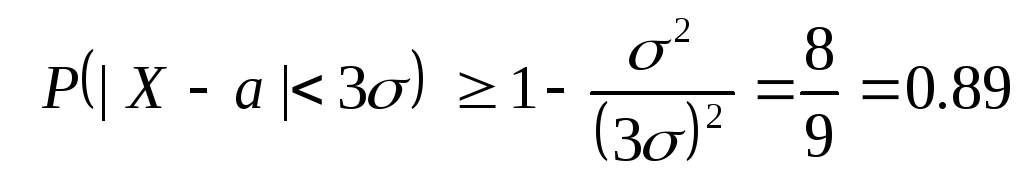 .
.
ทางนี้, โดยทั่วไปเราสามารถประมาณความน่าจะเป็นของตัวแปรสุ่มที่เบี่ยงเบนไปจากค่าเฉลี่ยโดยค่าเบี่ยงเบนมาตรฐานไม่เกินสามค่าด้วยตัวเลข 0.89 ในขณะที่การแจกแจงแบบปกติสามารถรับประกันได้ด้วยความน่าจะเป็น 0.997 .
ความไม่เท่าเทียมกันของ Chebyshev สามารถนำไปใช้กับระบบของตัวแปรสุ่มที่กระจายอย่างเหมือนกันอย่างอิสระ
ความไม่เท่าเทียมกันทั่วไปของ Chebyshev. ถ้าตัวแปรสุ่มอิสระ X 1 , X 2 , … , X น เอ็ม(X ผม )= เอและการกระจายตัว ดี(X ผม )= ดี, แล้ว
ที่ น=1 ความไม่เท่าเทียมกันนี้นำไปสู่ความไม่เท่าเทียมกันของ Chebyshev ที่กำหนดไว้ข้างต้น
ความไม่เท่าเทียมกันของ Chebyshev ซึ่งมีความสำคัญอย่างอิสระในการแก้ปัญหาที่เกี่ยวข้อง ใช้เพื่อพิสูจน์ทฤษฎีบท Chebyshev ที่เรียกว่า ก่อนอื่นเราจะอธิบายแก่นแท้ของทฤษฎีบทนี้แล้วจึงกำหนดสูตรที่เป็นทางการ
อนุญาต X 1
, X 2
, … , X น– ตัวแปรสุ่มอิสระจำนวนมากพร้อมความคาดหวังทางคณิตศาสตร์ M(X .) 1
)=a 1
, … , M(X น )=a น. แม้ว่าผลลัพธ์จากการทดลองแต่ละรายการสามารถหาค่าได้ไกลจากค่าเฉลี่ย (เช่น การคาดหมายทางคณิตศาสตร์) อย่างไรก็ตาม ตัวแปรสุ่ม  เท่ากับค่าเฉลี่ยเลขคณิต โดยมีความน่าจะเป็นสูงจะได้ค่าใกล้เคียงกับจำนวนคงที่
เท่ากับค่าเฉลี่ยเลขคณิต โดยมีความน่าจะเป็นสูงจะได้ค่าใกล้เคียงกับจำนวนคงที่  (นี่คือค่าเฉลี่ยของความคาดหวังทางคณิตศาสตร์ทั้งหมด) ซึ่งหมายความถึงสิ่งต่อไปนี้ ให้จากการทดสอบตัวแปรสุ่มอิสระ X 1
, X 2
, … , X น(มีเยอะมาก!) ได้นำเอาค่านิยมตามนั้น X 1
, X 2
, … , X นตามลำดับ แล้วถ้าค่าเหล่านี้เองอาจกลายเป็นว่าอยู่ไกลจากค่าเฉลี่ยของตัวแปรสุ่มที่สอดคล้องกัน ค่าเฉลี่ยของพวกมัน
(นี่คือค่าเฉลี่ยของความคาดหวังทางคณิตศาสตร์ทั้งหมด) ซึ่งหมายความถึงสิ่งต่อไปนี้ ให้จากการทดสอบตัวแปรสุ่มอิสระ X 1
, X 2
, … , X น(มีเยอะมาก!) ได้นำเอาค่านิยมตามนั้น X 1
, X 2
, … , X นตามลำดับ แล้วถ้าค่าเหล่านี้เองอาจกลายเป็นว่าอยู่ไกลจากค่าเฉลี่ยของตัวแปรสุ่มที่สอดคล้องกัน ค่าเฉลี่ยของพวกมัน  มีแนวโน้มที่จะใกล้เคียงกับ
มีแนวโน้มที่จะใกล้เคียงกับ  . ดังนั้น ค่าเฉลี่ยเลขคณิตของตัวแปรสุ่มจำนวนมากจึงสูญเสียอักขระสุ่มไปและสามารถทำนายได้อย่างแม่นยำมาก สิ่งนี้สามารถอธิบายได้ด้วยความจริงที่ว่าค่าเบี่ยงเบนแบบสุ่มของค่า X ผมจาก เอ ผมอาจมีสัญญาณต่างกัน ดังนั้นโดยรวมแล้ว การเบี่ยงเบนเหล่านี้จะได้รับการชดเชยด้วยความน่าจะเป็นสูง
. ดังนั้น ค่าเฉลี่ยเลขคณิตของตัวแปรสุ่มจำนวนมากจึงสูญเสียอักขระสุ่มไปและสามารถทำนายได้อย่างแม่นยำมาก สิ่งนี้สามารถอธิบายได้ด้วยความจริงที่ว่าค่าเบี่ยงเบนแบบสุ่มของค่า X ผมจาก เอ ผมอาจมีสัญญาณต่างกัน ดังนั้นโดยรวมแล้ว การเบี่ยงเบนเหล่านี้จะได้รับการชดเชยด้วยความน่าจะเป็นสูง
Terema Chebyshev (กฎของตัวเลขจำนวนมากในรูปแบบของ Chebyshev) อนุญาต X 1 , X 2 , … , X น … เป็นลำดับของตัวแปรสุ่มอิสระแบบคู่ซึ่งความแปรปรวนจำกัดอยู่ที่จำนวนเดียวกัน จากนั้น ไม่ว่าเราจะหาจำนวน ε น้อยเพียงใด ความน่าจะเป็นของอสมการ
จะเข้าใกล้ความสามัคคีโดยพลการถ้าจำนวน นตัวแปรสุ่มให้มีขนาดใหญ่พอ อย่างเป็นทางการหมายความว่าภายใต้เงื่อนไขของทฤษฎีบท
การบรรจบกันประเภทนี้เรียกว่าคอนเวอร์เจนซ์ในความน่าจะเป็นและแสดงโดย:
ดังนั้น ทฤษฎีบทของ Chebyshev จึงกล่าวว่า หากมีตัวแปรสุ่มอิสระจำนวนมากเพียงพอ ค่าเฉลี่ยเลขคณิตของพวกมันในการทดสอบครั้งเดียวก็จะได้ค่าที่ใกล้เคียงกับค่าเฉลี่ยของความคาดหวังทางคณิตศาสตร์อย่างแน่นอน
ส่วนใหญ่มักใช้ทฤษฎีบท Chebyshev ในสถานการณ์ที่ตัวแปรสุ่ม X 1 , X 2 , … , X น … มีการแจกแจงแบบเดียวกัน (เช่น กฎการแจกแจงแบบเดียวกันหรือความหนาแน่นของความน่าจะเป็นเท่ากัน) อันที่จริง นี่เป็นเพียงอินสแตนซ์จำนวนมากของตัวแปรสุ่มตัวเดียวกัน
ผลที่ตามมา(ของความไม่เท่าเทียมกันทั่วไปของ Chebyshev) ถ้าตัวแปรสุ่มอิสระ X 1 , X 2 , … , X น … มีการแจกแจงแบบเดียวกันกับความคาดหวังทางคณิตศาสตร์ เอ็ม(X ผม )= เอและการกระจายตัว ดี(X ผม )= ดี, แล้ว
 , เช่น.
, เช่น.  .
.
หลักฐานดังต่อไปนี้จากความไม่เท่าเทียมกันทั่วไปของ Chebyshev โดยผ่านไปยังขีด จำกัด as น→∞ .
เราทราบอีกครั้งว่าความเท่าเทียมกันที่เขียนไว้ข้างต้นไม่ได้รับประกันว่ามูลค่าของปริมาณ  มีแนวโน้มที่จะ เอที่ น→∞. ค่านี้ยังคงเป็นตัวแปรสุ่มและค่าแต่ละค่าก็ค่อนข้างห่างไกลจาก เอ. แต่ความน่าจะเป็นดังกล่าว (ห่างไกลจาก เอ) มีค่าเพิ่มขึ้น นมีแนวโน้มเป็น 0
มีแนวโน้มที่จะ เอที่ น→∞. ค่านี้ยังคงเป็นตัวแปรสุ่มและค่าแต่ละค่าก็ค่อนข้างห่างไกลจาก เอ. แต่ความน่าจะเป็นดังกล่าว (ห่างไกลจาก เอ) มีค่าเพิ่มขึ้น นมีแนวโน้มเป็น 0
ความคิดเห็น. ข้อสรุปของผลสืบเนื่องก็เห็นได้ชัดในกรณีทั่วไปมากขึ้นเมื่อตัวแปรสุ่มอิสระ X 1 , X 2 , … , X น … มีการแจกแจงต่างกัน แต่มีความคาดหวังทางคณิตศาสตร์เหมือนกัน (equal เอ) และความแปรปรวนจำกัดโดยรวม ทำให้สามารถคาดการณ์ความถูกต้องของการวัดปริมาณหนึ่งๆ ได้ แม้ว่าการวัดเหล่านี้จะทำโดยใช้เครื่องมือต่างกันก็ตาม
ให้เราพิจารณารายละเอียดเพิ่มเติมเกี่ยวกับการประยุกต์ใช้ผลลัพธ์นี้กับการวัดปริมาณ มาใช้อุปกรณ์กัน นการวัดปริมาณเท่ากัน มูลค่าที่แท้จริงคือ เอและเราไม่รู้ ผลของการวัดดังกล่าว X 1
, X 2
, … , X นอาจมีความแตกต่างกันอย่างมีนัยสำคัญ (และจากมูลค่าที่แท้จริง เอ) เนื่องจากปัจจัยสุ่มต่างๆ (แรงดันตก อุณหภูมิ การสั่นสะเทือนแบบสุ่ม ฯลฯ) พิจารณา r.v. X- การอ่านค่าเครื่องมือสำหรับการวัดปริมาณครั้งเดียวและชุดของ r.v. X 1
, X 2
, … , X น- การอ่านค่าเครื่องครั้งแรก ครั้งที่สอง ... การวัดครั้งสุดท้าย ดังนั้นแต่ละปริมาณ X 1
, X 2
, … , X น
มีเพียงหนึ่งในกรณีของ r.v. Xดังนั้นพวกมันทั้งหมดจึงมีการแจกแจงแบบเดียวกับ r.v. X. เนื่องจากผลการวัดเป็นอิสระจากกัน ดังนั้น r.v. X 1
, X 2
, … , X นถือว่าเป็นอิสระได้ หากอุปกรณ์ไม่ได้ให้ข้อผิดพลาดอย่างเป็นระบบ (เช่น ศูนย์ไม่ได้ "ล้มลง" บนมาตราส่วน สปริงไม่ยืดออก ฯลฯ) เราก็สามารถสันนิษฐานได้ว่าการคาดหมายทางคณิตศาสตร์ M(X) = a, และดังนั้นจึง M(X .) 1
) = ... = M(X น ) = a. ดังนั้นเงื่อนไขของผลสืบเนื่องข้างต้นเป็นที่พอใจและเป็นค่าประมาณของปริมาณ เอเราสามารถ "ดำเนินการ" ของตัวแปรสุ่มได้  ในการทดลองของเรา (ประกอบด้วยชุดของ นการวัด) เช่น
ในการทดลองของเรา (ประกอบด้วยชุดของ นการวัด) เช่น
 .
.
ด้วยการวัดจำนวนมาก จึงวางใจได้จริง แม่นดีการคำนวณโดยใช้สูตรนี้ นี่คือเหตุผลของหลักการในทางปฏิบัติที่ว่า ด้วยการวัดจำนวนมาก ค่าเฉลี่ยเลขคณิตของพวกมันแทบไม่แตกต่างจากมูลค่าที่แท้จริงของปริมาณที่วัดได้มากนัก
วิธีการ "สุ่มตัวอย่าง" ซึ่งใช้กันอย่างแพร่หลายในสถิติทางคณิตศาสตร์นั้นขึ้นอยู่กับกฎของตัวเลขจำนวนมาก ซึ่งช่วยให้ได้ลักษณะวัตถุประสงค์ด้วยความแม่นยำที่ยอมรับได้จากตัวอย่างค่าตัวแปรสุ่มที่ค่อนข้างน้อย แต่จะกล่าวถึงในหัวข้อถัดไป
ตัวอย่าง. บนอุปกรณ์วัดที่ไม่ทำให้เกิดการบิดเบือนอย่างเป็นระบบจะมีการวัดปริมาณที่แน่นอน เอครั้งเดียว (ได้รับค่า X 1
) และอีก 99 ครั้ง (ค่า X 2
, … , X 100
). สำหรับมูลค่าที่แท้จริงของการวัด เอขั้นแรกเอาผลการวัดครั้งแรก  แล้วค่าเฉลี่ยเลขคณิตของการวัดทั้งหมด
แล้วค่าเฉลี่ยเลขคณิตของการวัดทั้งหมด  . ความแม่นยำในการวัดของอุปกรณ์นั้นมีค่าเบี่ยงเบนมาตรฐานของการวัด σ ไม่เกิน 1 (เนื่องจากการกระจายตัว ดี=σ
2
ยังไม่เกิน 1). สำหรับแต่ละวิธีการวัด ให้ประมาณความน่าจะเป็นที่ข้อผิดพลาดในการวัดไม่เกิน 2
. ความแม่นยำในการวัดของอุปกรณ์นั้นมีค่าเบี่ยงเบนมาตรฐานของการวัด σ ไม่เกิน 1 (เนื่องจากการกระจายตัว ดี=σ
2
ยังไม่เกิน 1). สำหรับแต่ละวิธีการวัด ให้ประมาณความน่าจะเป็นที่ข้อผิดพลาดในการวัดไม่เกิน 2
วิธีการแก้. ให้ r.v. X- การอ่านค่าเครื่องมือสำหรับการวัดครั้งเดียว แล้วตามเงื่อนไข M(X)=a. ในการตอบคำถาม เราใช้ความไม่เท่าเทียมกันทั่วไปของ Chebyshev

สำหรับ ε =2
ครั้งแรกสำหรับ น=1
แล้วสำหรับ น=100
. ในกรณีแรกเราได้รับ  และในครั้งที่สอง ดังนั้น กรณีที่สองจึงรับประกันความแม่นยำในการวัดที่กำหนดได้จริง ในขณะที่กรณีแรกทำให้เกิดข้อสงสัยอย่างมากในแง่นี้
และในครั้งที่สอง ดังนั้น กรณีที่สองจึงรับประกันความแม่นยำในการวัดที่กำหนดได้จริง ในขณะที่กรณีแรกทำให้เกิดข้อสงสัยอย่างมากในแง่นี้
ให้เรานำข้อความข้างต้นไปใช้กับตัวแปรสุ่มที่เกิดขึ้นในรูปแบบเบอร์นูลลี ให้เราระลึกถึงสาระสำคัญของโครงการนี้ ปล่อยให้มันผลิต น การทดสอบอิสระในแต่ละเหตุการณ์ แต่สามารถปรากฏด้วยความน่าจะเป็นเท่ากัน R, แ q=1–r(ตามความหมาย นี่คือความน่าจะเป็นของเหตุการณ์ตรงกันข้าม ไม่ใช่การเกิดขึ้นของเหตุการณ์ แต่) . มาใช้เลขกัน นการทดสอบดังกล่าว พิจารณาตัวแปรสุ่ม: X 1 – จำนวนครั้งของเหตุการณ์ แต่ใน 1 ทดสอบ, ..., X น– จำนวนครั้งของเหตุการณ์ แต่ใน นการทดสอบครั้ง ทั้งหมดแนะนำ r.v. สามารถรับค่าได้ 0 หรือ 1 (เหตุการณ์ แต่อาจปรากฏในการทดสอบหรือไม่) และค่า 1 ยอมรับแบบมีเงื่อนไขในการทดลองแต่ละครั้งด้วยความน่าจะเป็น พี(ความน่าจะเป็นของเหตุการณ์ แต่ในการทดสอบแต่ละครั้ง) และค่า 0 ด้วยความน่าจะเป็น q= 1 – พี. ดังนั้น ปริมาณเหล่านี้จึงมีกฎการจำหน่ายเหมือนกัน:
|
X 1 | ||
|
X น | ||
ดังนั้นค่าเฉลี่ยของปริมาณเหล่านี้และการกระจายก็เหมือนกัน: M(X .) 1 )=0 ∙ q+1 ∙ p= p, …, M(X น )= พี ; ดี(X 1 )=(0 2 ∙ q+1 2 ∙ พี)− พี 2 = พี∙(1− พี)= พี ∙ q, … , ดี(X น )= พี ∙ ถาม เราได้รับค่าเหล่านี้แทนค่าความไม่เท่าเทียมกันทั่วไปของ Chebyshev
 .
.
เป็นที่ชัดเจนว่า r.v. X=X 1 +…+Х นคือจำนวนครั้งของเหตุการณ์ แต่ทั้งหมด นการทดลอง (ตามที่พวกเขาพูด - "จำนวนความสำเร็จ" ใน นการทดสอบ) ปล่อยให้ใน นเหตุการณ์ทดสอบ แต่ปรากฏใน k ของพวกเขา. จากนั้นอสมการก่อนหน้าสามารถเขียนเป็น
 .
.
แต่ขนาด  , เท่ากับอัตราส่วนของจำนวนเหตุการณ์ที่เกิดขึ้น แต่ใน นการทดลองอิสระ กับจำนวนการทดลองทั้งหมด ก่อนหน้านี้เรียกว่าอัตราเหตุการณ์สัมพัทธ์ แต่ใน นการทดสอบ ดังนั้นจึงมีความไม่เท่าเทียมกัน
, เท่ากับอัตราส่วนของจำนวนเหตุการณ์ที่เกิดขึ้น แต่ใน นการทดลองอิสระ กับจำนวนการทดลองทั้งหมด ก่อนหน้านี้เรียกว่าอัตราเหตุการณ์สัมพัทธ์ แต่ใน นการทดสอบ ดังนั้นจึงมีความไม่เท่าเทียมกัน
 .
.
ทะลุขีดจำกัดแล้วที่ น→∞ เราได้  , เช่น.
, เช่น.  (ตามความน่าจะเป็น) นี่คือเนื้อหาของกฎหมายจำนวนมากในรูปแบบของเบอร์นูลลี จากนี้ไปจะมีการทดลองจำนวนมากพอสมควร นความเบี่ยงเบนเล็กน้อยโดยพลการของความถี่สัมพัทธ์
(ตามความน่าจะเป็น) นี่คือเนื้อหาของกฎหมายจำนวนมากในรูปแบบของเบอร์นูลลี จากนี้ไปจะมีการทดลองจำนวนมากพอสมควร นความเบี่ยงเบนเล็กน้อยโดยพลการของความถี่สัมพัทธ์  เหตุการณ์จากความน่าจะเป็น Rเกือบจะเป็นเหตุการณ์บางอย่าง และการเบี่ยงเบนครั้งใหญ่แทบจะเป็นไปไม่ได้เลย ผลลัพธ์ที่ได้เกี่ยวกับความเสถียรของความถี่สัมพัทธ์ดังกล่าว (ซึ่งก่อนหน้านี้เราเรียกว่า ทดลองข้อเท็จจริง) ให้เหตุผลกับคำจำกัดความทางสถิติที่นำมาใช้ก่อนหน้านี้ของความน่าจะเป็นของเหตุการณ์เป็นตัวเลขที่ความถี่สัมพัทธ์ของเหตุการณ์ผันผวน
เหตุการณ์จากความน่าจะเป็น Rเกือบจะเป็นเหตุการณ์บางอย่าง และการเบี่ยงเบนครั้งใหญ่แทบจะเป็นไปไม่ได้เลย ผลลัพธ์ที่ได้เกี่ยวกับความเสถียรของความถี่สัมพัทธ์ดังกล่าว (ซึ่งก่อนหน้านี้เราเรียกว่า ทดลองข้อเท็จจริง) ให้เหตุผลกับคำจำกัดความทางสถิติที่นำมาใช้ก่อนหน้านี้ของความน่าจะเป็นของเหตุการณ์เป็นตัวเลขที่ความถี่สัมพัทธ์ของเหตุการณ์ผันผวน
พิจารณาว่านิพจน์ พี∙
q=
พี∙(1−
พี)=
พี−
พี 2
ไม่เกินช่วงการเปลี่ยนแปลง  (ง่ายต่อการตรวจสอบโดยหาค่าต่ำสุดของฟังก์ชันในส่วนนี้) จากอสมการข้างต้น
(ง่ายต่อการตรวจสอบโดยหาค่าต่ำสุดของฟังก์ชันในส่วนนี้) จากอสมการข้างต้น  หาง่าย
หาง่าย
 ,
,
ซึ่งใช้ในการแก้ปัญหาที่เกี่ยวข้อง (หนึ่งในนั้นจะได้รับด้านล่าง)
ตัวอย่าง. เหรียญถูกพลิก 1,000 ครั้ง ประมาณความน่าจะเป็นที่ความเบี่ยงเบนของความถี่สัมพัทธ์ของลักษณะที่ปรากฏของเสื้อคลุมแขนจากความน่าจะเป็นจะน้อยกว่า 0.1
วิธีการแก้. การใช้ความไม่เท่าเทียมกัน  ที่ พี=
q=1/2
,
น=1000
,
ε=0.1, เราได้รับ .
ที่ พี=
q=1/2
,
น=1000
,
ε=0.1, เราได้รับ .
ตัวอย่าง. ประมาณความน่าจะเป็นที่ภายใต้เงื่อนไขของตัวอย่างก่อนหน้านี้ ตัวเลข kของเสื้อคลุมแขนที่ลดลงจะอยู่ในช่วงของ 400 ก่อน 600 .
วิธีการแก้. สภาพ 400<
k<600
หมายความว่า 400/1000<
k/
น<600/1000
, เช่น. 0.4<
W น (อา)<0.6
หรือ  . ดังที่เราได้เห็นจากตัวอย่างก่อนหน้านี้ ความน่าจะเป็นของเหตุการณ์ดังกล่าวอย่างน้อยก็ 0.975
.
. ดังที่เราได้เห็นจากตัวอย่างก่อนหน้านี้ ความน่าจะเป็นของเหตุการณ์ดังกล่าวอย่างน้อยก็ 0.975
.
ตัวอย่าง. เพื่อคำนวณความน่าจะเป็นของเหตุการณ์บางอย่าง แต่มีการทดลอง 1,000 ครั้งซึ่งเหตุการณ์ แต่ปรากฏตัว 300 ครั้ง ประมาณความน่าจะเป็นที่ความถี่สัมพัทธ์ (เท่ากับ 300/1000=0.3) แตกต่างจากความน่าจะเป็นจริง Rไม่เกิน 0.1
วิธีการแก้. ใช้ความไม่เท่าเทียมกันข้างต้น  สำหรับ n=1000 ε=0.1 เราได้รับ
สำหรับ n=1000 ε=0.1 เราได้รับ
กฎของตัวเลขขนาดใหญ่
กฎของตัวเลขจำนวนมากในทฤษฎีความน่าจะเป็นระบุว่าค่าเฉลี่ยเชิงประจักษ์ (ค่าเฉลี่ยเลขคณิต) ของตัวอย่างที่มีขอบเขตจำกัดขนาดใหญ่เพียงพอจากการแจกแจงแบบตายตัวนั้นใกล้เคียงกับค่าเฉลี่ยทางทฤษฎี (ความคาดหวัง) ของการแจกแจงนี้ ขึ้นอยู่กับประเภทของการบรรจบกัน มีกฎที่อ่อนแอของจำนวนมาก เมื่อมีการลู่เข้าในความน่าจะเป็น และกฎที่แข็งแกร่งของจำนวนมาก เมื่อมีการบรรจบกันเกือบทุกที่
จะมีการทดลองจำนวนมากเสมอซึ่งด้วยความน่าจะเป็นที่กำหนดไว้ล่วงหน้า ความถี่สัมพัทธ์ของการเกิดขึ้นของเหตุการณ์บางอย่างจะแตกต่างจากความน่าจะเป็นเพียงเล็กน้อยโดยพลการ
ความหมายทั่วไปของกฎจำนวนมากคือการกระทำร่วมกันของปัจจัยสุ่มจำนวนมากนำไปสู่ผลลัพธ์ที่เกือบจะไม่ขึ้นกับโอกาส
วิธีการประมาณความน่าจะเป็นตามการวิเคราะห์กลุ่มตัวอย่างที่มีขอบเขตจะขึ้นอยู่กับคุณสมบัตินี้ ตัวอย่างที่ดีคือการทำนายผลการเลือกตั้งจากการสำรวจกลุ่มตัวอย่างผู้มีสิทธิเลือกตั้ง
กฎหมายที่อ่อนแอของตัวเลขจำนวนมาก
ให้มีลำดับอนันต์ (การแจงนับติดต่อกัน) ของตัวแปรสุ่มแบบกระจายและไม่สัมพันธ์กันซึ่งกำหนดไว้บนช่องว่างความน่าจะเป็นเดียวกัน นั่นคือความแปรปรวนร่วมของพวกเขา อนุญาต . ให้เราแสดงค่าเฉลี่ยตัวอย่างของเทอมแรก:
กฎที่แข็งแกร่งของตัวเลขจำนวนมาก
ให้มีลำดับอนันต์ของตัวแปรสุ่มแบบกระจายที่เหมือนกันอิสระ ซึ่งกำหนดไว้บนช่องว่างความน่าจะเป็นเดียวกัน อนุญาต . ให้เราแสดงค่าเฉลี่ยตัวอย่างของเทอมแรก:
.แล้วเกือบจะแน่นอน
ดูสิ่งนี้ด้วย
วรรณกรรม
- Shiryaev A. N.ความน่าจะเป็น - ม.: วิทยาศาสตร์ 1989.
- Chistyakov V.P.หลักสูตรทฤษฎีความน่าจะเป็น - ม., 1982.
มูลนิธิวิกิมีเดีย 2010 .
- การถ่ายทำภาพยนตร์ของรัสเซีย
- โกรเมก้า, มิคาอิล สเตฟาโนวิช
ดูว่า "กฎของตัวเลขมาก" ในพจนานุกรมอื่นๆ คืออะไร:
กฎหมายจำนวนมหาศาล- (กฎแห่งตัวเลขมาก) ในกรณีที่พฤติกรรมของสมาชิกแต่ละคนของประชากรมีความโดดเด่นอย่างมาก พฤติกรรมของกลุ่มโดยเฉลี่ยนั้นคาดเดาได้มากกว่าพฤติกรรมของสมาชิกคนใดคนหนึ่ง แนวโน้มที่กลุ่ม ... ... พจนานุกรมเศรษฐกิจ
กฎหมายจำนวนมหาศาล- ดูกฎหมายตัวเลขขนาดใหญ่ อันตินาซี สารานุกรมสังคมวิทยา 2552 ... สารานุกรมสังคมวิทยา
กฎของตัวเลขขนาดใหญ่- หลักการตามแบบแผนเชิงปริมาณที่มีอยู่ในปรากฏการณ์ทางสังคมแบบมวลชนนั้นแสดงออกอย่างชัดเจนที่สุดด้วยการสังเกตจำนวนมากพอสมควร ปรากฏการณ์เดียวมีความอ่อนไหวต่อผลกระทบของการสุ่มและ ... ... อภิธานศัพท์ของเงื่อนไขทางธุรกิจ
กฎหมายจำนวนมหาศาล- อ้างว่าด้วยความน่าจะเป็นที่ใกล้หนึ่ง ค่าเฉลี่ยเลขคณิตของตัวแปรสุ่มจำนวนมากที่มีลำดับเดียวกันโดยประมาณจะแตกต่างกันเล็กน้อยจากค่าคงที่ที่เท่ากับค่าเฉลี่ยเลขคณิตของความคาดหวังทางคณิตศาสตร์ของตัวแปรเหล่านี้ ความแตกต่าง… … สารานุกรมธรณีวิทยา
กฎของตัวเลขจำนวนมาก- — [Ya.N. Luginsky, M.S. Fezi Zhilinskaya, Yu.S. Kabirov English Russian Dictionary of Electrical Engineering and Power Industry, มอสโก, 1999] หัวข้อวิศวกรรมไฟฟ้า, แนวคิดพื้นฐาน EN กฎหมายของค่าเฉลี่ยกฎหมายจำนวนมาก ... คู่มือนักแปลทางเทคนิค
กฎของตัวเลขจำนวนมาก- didžiųjų skaičių dėsnis statusas T sritis fizika atitikmenys: engl. กฎของตัวเลขจำนวนมาก Gesetz der großen Zahlen, n rus. กฎหมายจำนวนมาก, ม. loi des grands nombres, f … Fizikos ปลายทาง žodynas
กฎหมายจำนวนมหาศาล- หลักการทั่วไป เนื่องจากการกระทำร่วมกันของปัจจัยสุ่มนำไปสู่ผลลัพธ์ที่เกือบจะเป็นอิสระจากโอกาสภายใต้เงื่อนไขทั่วไปบางประการ การบรรจบกันของความถี่ของการเกิดเหตุการณ์สุ่มด้วยความน่าจะเป็นด้วยการเพิ่มจำนวน ... ... สารานุกรมสังคมวิทยารัสเซีย
กฎของตัวเลขขนาดใหญ่- กฎหมายระบุว่าการกระทำสะสมของปัจจัยสุ่มจำนวนมากนำไปสู่ผลลัพธ์ที่เกือบจะเป็นอิสระจากโอกาสภายใต้เงื่อนไขทั่วไปบางประการ ... สังคมวิทยา: พจนานุกรม
กฎหมายจำนวนมหาศาล- กฎหมายสถิติแสดงความสัมพันธ์ของตัวบ่งชี้ทางสถิติ (พารามิเตอร์) ของกลุ่มตัวอย่างและประชากรทั่วไป ค่าจริงของตัวบ่งชี้ทางสถิติที่ได้จากตัวอย่างบางตัวจะแตกต่างจากค่าที่เรียกว่าเสมอ ทฤษฎี ...... สังคมวิทยา: สารานุกรม
กฎหมายจำนวนมหาศาล- หลักการที่ว่าความถี่ของการสูญเสียทางการเงินบางประเภทสามารถทำนายได้อย่างแม่นยำสูงเมื่อมีการสูญเสียประเภทที่คล้ายกันจำนวนมาก ... พจนานุกรมสารานุกรมเศรษฐศาสตร์และกฎหมาย
หนังสือ
- ชุดโต๊ะ. คณิตศาสตร์. ทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์. 6 ตาราง + วิธีการ, . โต๊ะพิมพ์บนกระดาษแข็งโพลีกราฟิกหนา ขนาด 680 x 980 มม. ชุดนี้ประกอบด้วยโบรชัวร์พร้อมคำแนะนำเกี่ยวกับระเบียบวิธีวิจัยสำหรับครูผู้สอน อัลบั้มการศึกษา 6 แผ่น สุ่ม…
เคล็ดลับของผู้ขายที่ประสบความสำเร็จคืออะไร? หากคุณดูพนักงานขายที่เก่งที่สุดของบริษัทใดๆ คุณจะสังเกตเห็นว่าพวกเขามีสิ่งหนึ่งที่เหมือนกัน แต่ละคนพบปะกับผู้คนมากขึ้นและนำเสนอผลงานมากกว่าพนักงานขายที่ประสบความสำเร็จน้อยกว่า คนเหล่านี้เข้าใจดีว่าการขายเป็นเกมตัวเลข และยิ่งพวกเขาบอกเกี่ยวกับผลิตภัณฑ์หรือบริการของพวกเขามากเท่าไร พวกเขาก็ยิ่งปิดการขายมากขึ้นเท่านั้น พวกเขาเข้าใจดีว่าหากพวกเขาสื่อสารไม่เพียงแค่กับคนไม่กี่คนที่จะตอบตกลงกับพวกเขาอย่างแน่นอน แต่ยังรวมถึงผู้ที่มีความสนใจในข้อเสนอของพวกเขาที่ไม่ค่อยดีนักด้วย กฎของค่าเฉลี่ยก็จะเป็นประโยชน์ต่อพวกเขา
รายได้ของคุณจะขึ้นอยู่กับจำนวนการขาย แต่ในขณะเดียวกัน รายได้ก็จะแปรผันตรงกับจำนวนการนำเสนอที่คุณทำ เมื่อคุณเข้าใจและเริ่มใช้กฎแห่งค่าเฉลี่ยแล้ว ความวิตกกังวลที่เกี่ยวข้องกับการเริ่มต้นธุรกิจใหม่หรือการทำงานในสาขาใหม่จะเริ่มลดลง และด้วยเหตุนี้ ความรู้สึกในการควบคุมและความมั่นใจในความสามารถในการหารายได้จึงเริ่มเติบโตขึ้น หากคุณเพียงแค่ทำการนำเสนอและฝึกฝนทักษะของคุณในกระบวนการนี้ ก็จะมีข้อตกลง
แทนที่จะคิดถึงจำนวนข้อเสนอ ให้นึกถึงจำนวนการนำเสนอ มันไม่สมเหตุสมผลเลยที่จะตื่นเช้าหรือกลับบ้านในตอนเย็นแล้วเริ่มสงสัยว่าใครจะซื้อผลิตภัณฑ์ของคุณ แต่ควรวางแผนในแต่ละวันว่าต้องโทรกี่ครั้ง แล้วไม่ว่าจะเกิดอะไรขึ้น - โทรออกทั้งหมด! วิธีนี้จะทำให้งานของคุณง่ายขึ้น เพราะเป็นเป้าหมายที่ง่ายและเจาะจง หากคุณรู้ว่าคุณมีเป้าหมายที่เจาะจงและสามารถบรรลุได้ต่อหน้าคุณ คุณจะสามารถกำหนดจำนวนการโทรที่วางแผนไว้ได้ง่ายขึ้น หากคุณได้ยินคำว่า "ใช่" สองสามครั้งในระหว่างขั้นตอนนี้ ยิ่งดี!
และถ้า "ไม่" ในตอนเย็น คุณจะรู้สึกว่าคุณได้ทำทุกอย่างที่ทำได้โดยสุจริต และคุณจะไม่ถูกทรมานด้วยความคิดเกี่ยวกับจำนวนเงินที่คุณได้รับ หรือจำนวนหุ้นส่วนที่คุณได้รับในหนึ่งวัน
สมมติว่าในบริษัทหรือธุรกิจของคุณ พนักงานขายโดยเฉลี่ยจะปิดหนึ่งข้อเสนอทุกๆ สี่การนำเสนอ ลองนึกภาพว่าคุณกำลังจั่วไพ่จากสำรับ การ์ดแต่ละใบที่มีสามชุด - โพดำ เพชร และไม้กอล์ฟ - เป็นงานนำเสนอที่คุณนำเสนอผลิตภัณฑ์ บริการ หรือโอกาสอย่างมืออาชีพ คุณทำดีที่สุดแล้ว แต่คุณยังไม่ปิดดีล และการ์ดหัวใจแต่ละใบเป็นข้อตกลงที่ช่วยให้คุณได้รับเงินหรือหาเพื่อนใหม่
ในสถานการณ์เช่นนี้ คุณไม่ต้องการที่จะจั่วไพ่จากสำรับให้มากที่สุดเท่าที่จะมากได้หรือ? สมมติว่าคุณได้รับการเสนอให้จั่วไพ่ได้มากเท่าที่คุณต้องการ ในขณะที่จ่ายเงินให้คุณหรือแนะนำเพื่อนใหม่ทุกครั้งที่คุณจั่วการ์ดหัวใจ คุณจะเริ่มจั่วไพ่อย่างกระตือรือร้น โดยแทบไม่สังเกตเห็นว่าไพ่ใบไหนถูกดึงออกมา
คุณรู้ไหมว่ามีหัวใจสิบสามดวงในสำรับไพ่ห้าสิบสองใบ และในสองสำรับ - การ์ดหัวใจ 26 ใบและอื่น ๆ คุณจะผิดหวังกับการวาดโพดำ เพชร หรือไม้กระบองหรือไม่? แน่นอนว่าไม่! คุณจะคิดว่า "คิดถึง" แต่ละครั้งจะทำให้คุณใกล้ชิดยิ่งขึ้น - อะไรนะ? ถึงการ์ดหัวใจ!
แต่คุณรู้อะไรไหม? คุณได้รับข้อเสนอนี้แล้ว คุณอยู่ในตำแหน่งที่ไม่เหมือนใครในการหารายได้มากเท่าที่คุณต้องการ และจั่วการ์ดหัวใจให้ได้มากเท่าที่คุณต้องการจะจั่วในชีวิตของคุณ และถ้าคุณเพียงแค่ "จั่วไพ่" อย่างมีสติ พัฒนาทักษะและอดทนกับจอบ เพชร และไม้กระบองเล็กๆ น้อยๆ คุณก็จะกลายเป็นพนักงานขายที่ยอดเยี่ยมและประสบความสำเร็จ
สิ่งหนึ่งที่ทำให้การขายสนุกมากคือทุกครั้งที่คุณสับไพ่ ไพ่จะถูกสับต่างกัน บางครั้งหัวใจทั้งหมดก็จบลงที่จุดเริ่มต้นของเด็คและหลังจากสตรีคที่ประสบความสำเร็จ (เมื่อดูเหมือนว่าเราจะไม่มีวันแพ้!) เรากำลังรอการ์ดแถวยาวของชุดที่แตกต่างกัน และอีกครั้ง ในการที่จะไปถึงหัวใจแรก คุณต้องผ่านจอบ กระบอง และแทมบูรีนจำนวนนับไม่ถ้วน และบางครั้งไพ่ชุดต่าง ๆ ก็หลุดออกมาอย่างเด็ดขาด แต่อย่างไรก็ตาม ในทุกสำรับที่มีไพ่ห้าสิบสองใบ ลำดับใด ๆ ก็มีหัวใจสิบสามดวงเสมอ เพียงแค่ดึงการ์ดออกมาจนกว่าคุณจะพบ
จาก: Leylya,
กฎของตัวเลขจำนวนมากในทฤษฎีความน่าจะเป็นระบุว่าค่าเฉลี่ยเชิงประจักษ์ (ค่าเฉลี่ยเลขคณิต) ของตัวอย่างที่มีขอบเขตจำกัดขนาดใหญ่เพียงพอจากการแจกแจงแบบตายตัวนั้นใกล้เคียงกับค่าเฉลี่ยทางทฤษฎี (ความคาดหวัง) ของการแจกแจงนี้ ขึ้นอยู่กับประเภทของการบรรจบกัน คนหนึ่งแยกแยะระหว่างกฎที่อ่อนแอของจำนวนมาก เมื่อมีการลู่เข้าในความน่าจะเป็น และกฎที่แข็งแกร่งของจำนวนมาก เมื่อมีการบรรจบกันแทบทุกแห่ง
มีการทดลองจำนวนจำกัดเสมอซึ่งมีความน่าจะเป็นน้อยกว่า 1 ความถี่สัมพัทธ์ของการเกิดขึ้นของเหตุการณ์บางอย่างจะแตกต่างจากความน่าจะเป็นเพียงเล็กน้อยโดยพลการ
ความหมายทั่วไปของกฎจำนวนมาก: การกระทำร่วมกันของปัจจัยสุ่มที่เหมือนกันและเป็นอิสระจำนวนมากนำไปสู่ผลลัพธ์ที่ไม่ขึ้นอยู่กับโอกาสในขอบเขต
วิธีการประมาณความน่าจะเป็นตามการวิเคราะห์กลุ่มตัวอย่างที่มีขอบเขตจะขึ้นอยู่กับคุณสมบัตินี้ ตัวอย่างที่ดีคือการทำนายผลการเลือกตั้งจากการสำรวจกลุ่มตัวอย่างผู้มีสิทธิเลือกตั้ง
สารานุกรม YouTube
1 / 5
✪ กฎของตัวเลขขนาดใหญ่
✪ 07 - ทฤษฎีความน่าจะเป็น กฎของตัวเลขขนาดใหญ่
✪ 42 กฎของตัวเลขขนาดใหญ่
✪ 1 - กฎจำนวนมากของ Chebyshev
✪ ป.11 บทเรียนที่ 25 โค้งเกาส์เซียน กฎของตัวเลขขนาดใหญ่
คำบรรยาย
ลองดูกฎของจำนวนมาก ซึ่งอาจเป็นกฎที่เข้าใจง่ายที่สุดในคณิตศาสตร์และทฤษฎีความน่าจะเป็น และเนื่องจากมันใช้ได้กับหลายสิ่งหลายอย่าง บางครั้งจึงใช้และเข้าใจผิด ขอนิยามความถูกต้องก่อน แล้วเราจะพูดถึงสัญชาตญาณ ลองหาตัวแปรสุ่มกัน สมมุติว่า X สมมุติว่าเรารู้ค่าคาดหมายทางคณิตศาสตร์หรือค่าเฉลี่ยประชากรของมัน กฎของตัวเลขมากบอกว่าถ้าเราเอาตัวอย่างการสังเกตจำนวน n-th ของตัวแปรสุ่มและหาค่าเฉลี่ยจำนวนการสังเกตเหล่านั้นทั้งหมด... ลองหาตัวแปรกัน เรียกมันว่า X โดยมีตัวห้อย n และขีดกลางอยู่ด้านบน นี่คือค่าเฉลี่ยเลขคณิตของจำนวนการสังเกตที่ n ของตัวแปรสุ่มของเรา นี่คือข้อสังเกตแรกของฉัน ฉันทำการทดลองหนึ่งครั้ง และทำการสังเกตนี้ จากนั้นทำอีกครั้ง และทำการสังเกตนี้ ฉันทำอีกครั้ง และได้สิ่งนี้ ฉันทำการทดลองนี้ n ครั้งแล้วหารด้วยจำนวนการสังเกตของฉัน นี่คือค่าเฉลี่ยตัวอย่างของฉัน นี่คือค่าเฉลี่ยของการสังเกตทั้งหมดที่ฉันทำ กฎของจำนวนมากบอกเราว่าค่าเฉลี่ยตัวอย่างจะเข้าใกล้ค่าเฉลี่ยของตัวแปรสุ่ม หรือผมยังสามารถเขียนว่าค่าเฉลี่ยตัวอย่างจะเข้าหาค่าเฉลี่ยประชากรสำหรับเลข n ที่เข้าสู่อนันต์ ฉันจะไม่แยกความแตกต่างที่ชัดเจนระหว่าง "ค่าประมาณ" กับ "การบรรจบกัน" แต่ฉันหวังว่าคุณจะเข้าใจโดยสัญชาตญาณว่า หากฉันเอาตัวอย่างที่ค่อนข้างใหญ่ตรงนี้ ฉันจะได้ค่าที่คาดหวังสำหรับประชากรทั้งหมด ฉันคิดว่าพวกคุณส่วนใหญ่เข้าใจโดยสัญชาตญาณว่าถ้าฉันทำแบบทดสอบเพียงพอกับตัวอย่างจำนวนมาก ในที่สุดการทดสอบจะให้ค่าที่ฉันคาดหวัง โดยคำนึงถึงความคาดหวังทางคณิตศาสตร์ ความน่าจะเป็น และทั้งหมดนั้น แต่ฉันคิดว่ามันมักจะไม่ชัดเจนว่าทำไมสิ่งนี้ถึงเกิดขึ้น และก่อนที่จะเริ่มอธิบายว่าเหตุใดจึงเป็นเช่นนั้น ข้าพเจ้าขอยกตัวอย่างที่เป็นรูปธรรมแก่ท่าน กฎของตัวเลขมากบอกเราว่า... สมมุติว่าเรามีตัวแปรสุ่ม X ซึ่งเท่ากับจำนวนหัวในการโยนเหรียญที่ถูกต้อง 100 ครั้ง ก่อนอื่น เราทราบความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่มนี้ นี่คือจำนวนของการโยนเหรียญหรือการทดลองคูณด้วยอัตราต่อรองของการทดลองใด ๆ ที่ประสบความสำเร็จ มันจึงเท่ากับ 50 นั่นคือ กฎของจำนวนมากบอกว่า ถ้าเราเอาตัวอย่าง หรือถ้าฉันเฉลี่ยการทดลองเหล่านี้ ฉันจะได้รับ .. ทดสอบครั้งแรก พลิกเหรียญ 100 ครั้ง หรือเอากล่องร้อยเหรียญ เขย่า แล้วนับว่าได้หัวไปกี่หัว ก็ได้ ว่า เลข 55 นี่จะเป็น X1. จากนั้นฉันก็เขย่ากล่องอีกครั้งและได้หมายเลข 65 จากนั้นอีกครั้ง - และฉันได้ 45 และฉันทำแบบนี้ n ครั้ง แล้วหารด้วยจำนวนครั้งของการทดลอง กฎของจำนวนมากบอกเราว่าค่าเฉลี่ยนี้ (ค่าเฉลี่ยของการสังเกตทั้งหมดของฉัน) จะมีแนวโน้มที่ 50 ในขณะที่ n จะมีแนวโน้มเป็นอนันต์ ตอนนี้ฉันอยากจะพูดเล็กน้อยเกี่ยวกับสาเหตุที่เกิดขึ้น หลายคนเชื่อว่าหากหลังจากการทดลอง 100 ครั้ง ผลลัพธ์ของฉันสูงกว่าค่าเฉลี่ย ตามกฎของความน่าจะเป็น ฉันควรมีหัวมากหรือน้อยเพื่อจะพูดเพื่อชดเชยส่วนต่าง นี่ไม่ใช่สิ่งที่จะเกิดขึ้นอย่างแน่นอน ซึ่งมักเรียกกันว่า "ความเข้าใจผิดของนักพนัน" ให้ฉันแสดงให้คุณเห็นความแตกต่าง ฉันจะใช้ตัวอย่างต่อไปนี้ ขอผมวาดกราฟ มาเปลี่ยนสีกันเถอะ นี่คือ n, แกน x ของผมคือ n นี่คือจำนวนการทดสอบที่ฉันจะเรียกใช้ และแกน y ของฉันจะเป็นค่าเฉลี่ยตัวอย่าง เรารู้ว่าค่าเฉลี่ยของตัวแปรตามอำเภอใจนี้คือ 50 ขอผมวาดนี่นะ นี่คือ 50 กลับไปที่ตัวอย่างของเรา ถ้า n คือ... ในระหว่างการทดสอบครั้งแรกของฉัน ฉันได้ 55 ซึ่งเป็นค่าเฉลี่ยของฉัน ฉันมีจุดป้อนข้อมูลเพียงจุดเดียว หลังจากการทดลองสองครั้ง ฉันได้ 65 ดังนั้นค่าเฉลี่ยของฉันจะเท่ากับ 65+55 หารด้วย 2 นั่นคือ 60 และค่าเฉลี่ยของฉันเพิ่มขึ้นเล็กน้อย จากนั้นฉันได้ 45 ซึ่งลดค่าเฉลี่ยเลขคณิตของฉันอีกครั้ง ฉันจะไม่พลอต 45 ในแผนภูมิ ตอนนี้ ฉันต้องการค่าเฉลี่ยทั้งหมด 45+65 เท่ากับเท่าไหร่? ขอผมคำนวณค่านี้เพื่อแทนจุด นั่นคือ 165 หารด้วย 3 นั่นคือ 53 ไม่ใช่ 55 ดังนั้นค่าเฉลี่ยลงไปที่ 55 อีกครั้ง เราสามารถดำเนินการทดสอบต่อไปได้ หลังจากที่เราทำการทดลองสามครั้งและได้ค่าเฉลี่ยนี้แล้ว หลายคนคิดว่าเทพเจ้าแห่งความน่าจะเป็นจะทำให้มันทำให้เราได้หัวน้อยลงในอนาคต การทดลองต่อไปอีกสองสามครั้งจะลดลงเพื่อลดค่าเฉลี่ยลง แต่ก็ไม่ได้เป็นเช่นนั้นเสมอไป ในอนาคตความน่าจะเป็นจะเท่าเดิมเสมอ ความน่าจะเป็นที่ฉันจะโยนหัวมักจะเป็น 50% ไม่ใช่ว่าในตอนแรกฉันจะได้จำนวนหัวที่แน่นอน มากกว่าที่ฉันคาดไว้ และทันใดนั้นหางก็หลุดออกมา นี่คือ "ความเข้าใจผิดของผู้เล่น" หากคุณได้จำนวนหัวที่ไม่สมส่วน ไม่ได้หมายความว่าในบางจุด คุณจะเริ่มมีจำนวนก้อยที่ไม่สมส่วน นี้ไม่เป็นความจริงทั้งหมด กฎของตัวเลขจำนวนมากบอกเราว่ามันไม่สำคัญ สมมุติว่าหลังจากการทดลองจำนวนหนึ่งที่จำกัด ค่าเฉลี่ยของคุณ... ความน่าจะเป็นนั้นค่อนข้างน้อย แต่ถึงกระนั้น... สมมติว่าค่าเฉลี่ยของคุณถึงจุดนี้ - 70 คุณกำลังคิดว่า "ว้าว เรามาไกลเกินคาดแล้ว" แต่กฎของตัวเลขจำนวนมากบอกว่าไม่สนว่าเราจะทำการทดสอบกี่ครั้ง เรายังมีการทดลองอีกมากมายรอเราอยู่ ความคาดหวังทางคณิตศาสตร์ของการทดลองนับไม่ถ้วนนี้ โดยเฉพาะอย่างยิ่งในสถานการณ์เช่นนี้ จะเป็นดังนี้ เมื่อคุณได้จำนวนจำกัดที่แสดงมูลค่ามหาศาล จำนวนอนันต์ที่บรรจบกับมันจะนำไปสู่ค่าที่คาดหวังอีกครั้ง แน่นอนว่านี่เป็นการตีความที่หลวมมาก แต่นี่คือสิ่งที่กฎจำนวนมากบอกเรา มันเป็นสิ่งสำคัญ เขาไม่ได้บอกเราว่าถ้าเราได้หัวเยอะ โอกาสที่จะได้รับก้อยจะเพิ่มขึ้นเพื่อชดเชย กฎข้อนี้บอกเราว่าไม่ว่าผลลัพธ์จะเป็นเช่นไรเมื่อมีการทดลองใช้จำนวนจำกัด ตราบใดที่คุณยังมีการทดลองใช้จำนวนนับไม่ถ้วนรอคุณอยู่ และถ้าคุณทำมากพอ คุณจะกลับมามีความคาดหวังอีกครั้ง นี่เป็นจุดสำคัญ คิดเกี่ยวกับมัน แต่นี้ไม่ได้ใช้ทุกวันในทางปฏิบัติกับลอตเตอรีและคาสิโนแม้ว่าจะทราบดีว่าถ้าคุณทำการทดสอบเพียงพอ ... เราสามารถคำนวณได้ ... ความน่าจะเป็นที่เราจะเบี่ยงเบนจากบรรทัดฐานอย่างจริงจังคืออะไร? แต่คาสิโนและลอตเตอรีทำงานทุกวันบนหลักการที่ว่าหากคุณรับคนมากพอ แน่นอน ในเวลาอันสั้น ด้วยตัวอย่างเล็กๆ น้อยๆ จะมีสักกี่คนที่ถูกแจ็กพอต แต่ในระยะยาว คาสิโนจะได้รับประโยชน์จากพารามิเตอร์ของเกมที่พวกเขาเชิญให้คุณเล่นเสมอ นี่เป็นหลักการความน่าจะเป็นที่สำคัญที่เข้าใจง่าย แม้ว่าบางครั้ง เมื่อมีการอธิบายให้คุณทราบอย่างเป็นทางการด้วยตัวแปรสุ่ม ทั้งหมดก็ดูสับสนเล็กน้อย กฎทั้งหมดนี้กล่าวว่ายิ่งมีตัวอย่างมากเท่าใด ค่าเฉลี่ยเลขคณิตของตัวอย่างเหล่านั้นก็จะยิ่งมาบรรจบกับค่าเฉลี่ยที่แท้จริงมากขึ้นเท่านั้น และเพื่อให้เฉพาะเจาะจงมากขึ้น ค่าเฉลี่ยเลขคณิตของกลุ่มตัวอย่างของคุณจะมาบรรจบกับความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่ม นั่นคือทั้งหมดที่ พบกันใหม่ในวิดีโอหน้า!
กฎหมายที่อ่อนแอของตัวเลขจำนวนมาก
กฎที่อ่อนแอของตัวเลขจำนวนมากเรียกอีกอย่างว่าทฤษฎีบทของเบอร์นูลลี ตามชื่อจาค็อบ Bernoulli ผู้พิสูจน์มันในปี ค.ศ. 1713
ให้มีลำดับอนันต์ (การแจงนับติดต่อกัน) ของตัวแปรสุ่มแบบกระจายและไม่สัมพันธ์กัน นั่นคือความแปรปรวนร่วมของพวกเขา c o v (X i , X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). อนุญาต . ระบุด้วยค่าเฉลี่ยตัวอย่างของค่าแรก n (\displaystyle n)สมาชิก:
.
แล้ว X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
นั่นคือสำหรับทุกแง่บวก ε (\displaystyle \varepsilon )
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}กฎที่แข็งแกร่งของตัวเลขจำนวนมาก
ให้มีลำดับอนันต์ของตัวแปรสุ่มแบบกระจายที่เหมือนกันอย่างอิสระ ( X ผม ) ผม = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty ))กำหนดไว้บนช่องว่างความน่าจะเป็นหนึ่งช่อง (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F)),\mathbb (P))). อนุญาต E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N) ). แสดงโดย X¯n (\displaystyle (\bar(X))_(n))ค่าเฉลี่ยตัวอย่างแรก n (\displaystyle n)สมาชิก:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i),\;n\in \mathbb (N) ).แล้ว X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu )เกือบตลอดเวลา.
Pr (lim n → ∞ X ¯ n = μ) = 1 (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ ขวา)=1.) .เช่นเดียวกับกฎคณิตศาสตร์ใดๆ กฎของตัวเลขจำนวนมากสามารถใช้ได้กับโลกแห่งความเป็นจริงภายใต้สมมติฐานที่ทราบกันดีเท่านั้น ซึ่งสามารถบรรลุได้อย่างแม่นยำในระดับหนึ่งเท่านั้น ตัวอย่างเช่น เงื่อนไขของการทดสอบต่อเนื่องมักจะไม่สามารถคงไว้ได้อย่างไม่มีกำหนดและมีความแม่นยำแน่นอน นอกจากนี้ กฎของตัวเลขจำนวนมากพูดถึง .เท่านั้น ความเป็นไปไม่ได้ค่าเบี่ยงเบนอย่างมีนัยสำคัญของค่าเฉลี่ยจากการคาดหมายทางคณิตศาสตร์
ค่าเฉลี่ยเป็นตัวบ่งชี้ทั่วไปที่สุดในสถิติ เนื่องจากสามารถใช้เพื่อจำแนกลักษณะประชากรตามคุณลักษณะที่แปรผันในเชิงปริมาณได้ ตัวอย่างเช่น ในการเปรียบเทียบค่าจ้างของคนงานของสองวิสาหกิจนั้น ค่าจ้างของคนงานสองคนนั้นไม่สามารถนำมาใช้ได้ เพราะมันทำหน้าที่เป็นตัวบ่งชี้ที่แตกต่างกันไป นอกจากนี้ยังไม่สามารถรับค่าจ้างทั้งหมดที่จ่ายในสถานประกอบการได้เนื่องจากขึ้นอยู่กับจำนวนพนักงาน หากเราหารค่าจ้างทั้งหมดของแต่ละองค์กรด้วยจำนวนพนักงาน เราสามารถเปรียบเทียบและกำหนดได้ว่าองค์กรใดมีค่าจ้างเฉลี่ยสูงกว่า
กล่าวอีกนัยหนึ่ง ค่าจ้างของประชากรแรงงานที่ศึกษาจะได้รับลักษณะทั่วไปในค่าเฉลี่ย เป็นการแสดงออกถึงลักษณะทั่วไปและแบบฉบับที่เป็นลักษณะของจำนวนคนงานทั้งหมดที่เกี่ยวข้องกับลักษณะที่ศึกษา ในค่านี้ จะแสดงการวัดทั่วไปของแอตทริบิวต์นี้ ซึ่งมีค่าต่างกันสำหรับหน่วยของประชากร
การกำหนดมูลค่าเฉลี่ย ค่าเฉลี่ยในสถิติเป็นลักษณะทั่วไปของชุดของปรากฏการณ์ที่คล้ายคลึงกันตามแอตทริบิวต์ที่แตกต่างกันในเชิงปริมาณ ค่าเฉลี่ยแสดงระดับของคุณลักษณะนี้ ซึ่งสัมพันธ์กับหน่วยประชากร ด้วยความช่วยเหลือของค่าเฉลี่ย จึงสามารถเปรียบเทียบมวลรวมต่างๆ ตามลักษณะที่แตกต่างกันได้ (รายได้ต่อหัว ผลผลิตพืชผล ต้นทุนการผลิตในสถานประกอบการต่างๆ)
ค่าเฉลี่ยมักจะสรุปความแปรผันเชิงปริมาณของลักษณะที่เรากำหนดลักษณะของประชากรภายใต้การศึกษาเสมอ และมีค่าเท่ากันในทุกหน่วยของประชากร ซึ่งหมายความว่าเบื้องหลังค่าเฉลี่ยใด ๆ จะมีชุดของการกระจายหน่วยของประชากรตามแอตทริบิวต์ที่แตกต่างกันเช่น ซีรีส์รูปแบบต่างๆ ในแง่นี้ ค่าเฉลี่ยโดยพื้นฐานแล้วแตกต่างจากค่าสัมพัทธ์และโดยเฉพาะอย่างยิ่งจากตัวบ่งชี้ความเข้ม ตัวบ่งชี้ความเข้มคืออัตราส่วนของปริมาตรของมวลรวมที่แตกต่างกันสองชนิด (เช่น การผลิตของ GDP ต่อหัว) ในขณะที่ค่าเฉลี่ยหนึ่งจะสรุปลักษณะขององค์ประกอบของมวลรวมตามลักษณะใดลักษณะหนึ่ง (เช่น ค่าเฉลี่ย ค่าจ้างคนงาน)
ค่าเฉลี่ยและกฎของตัวเลขจำนวนมากในการเปลี่ยนแปลงของตัวบ่งชี้เฉลี่ย แนวโน้มทั่วไปจะปรากฏภายใต้อิทธิพลของกระบวนการของการพัฒนาปรากฏการณ์โดยรวม ในขณะที่ในแต่ละกรณีแนวโน้มนี้อาจไม่ชัดเจน เป็นสิ่งสำคัญที่ค่าเฉลี่ยต้องอาศัยการสรุปข้อเท็จจริงจำนวนมาก ภายใต้เงื่อนไขนี้เท่านั้น พวกเขาจะเปิดเผยแนวโน้มทั่วไปที่อยู่ภายใต้กระบวนการโดยรวม
แก่นแท้ของกฎจำนวนมากและความสำคัญของกฎสำหรับค่าเฉลี่ย เมื่อจำนวนการสังเกตเพิ่มขึ้น มีความสมบูรณ์มากขึ้นเรื่อยๆ นั่นคือกฎของตัวเลขจำนวนมากสร้างเงื่อนไขสำหรับระดับทั่วไปของแอตทริบิวต์ที่แตกต่างกันเพื่อให้ปรากฏในค่าเฉลี่ยภายใต้เงื่อนไขสถานที่และเวลาที่เฉพาะเจาะจง คุณค่าของระดับนี้ถูกกำหนดโดยสาระสำคัญของปรากฏการณ์นี้
ประเภทของค่าเฉลี่ยค่าเฉลี่ยที่ใช้ในสถิติอยู่ในคลาสของหมายถึงกำลัง ซึ่งสูตรทั่วไปมีดังนี้:
โดยที่ x คือค่าเฉลี่ยกำลัง
X - การเปลี่ยนแปลงค่าของแอตทริบิวต์ (ตัวเลือก)
- ตัวเลือกหมายเลข
เลขชี้กำลังของค่าเฉลี่ย
เครื่องหมายบวก
สำหรับค่าต่าง ๆ ของเลขชี้กำลังของค่าเฉลี่ย จะได้ค่าเฉลี่ยประเภทต่างๆ:
ค่าเฉลี่ยเลขคณิต
ตาราง;
ลูกบาศก์เฉลี่ย
ฮาร์มอนิกเฉลี่ย
เฉลี่ยเรขาคณิต.
ค่าเฉลี่ยประเภทต่างๆ มีความหมายต่างกันเมื่อใช้สถิติแหล่งที่มาเดียวกัน ในขณะเดียวกัน ยิ่งเลขชี้กำลังของค่าเฉลี่ยมาก ค่าของค่าเฉลี่ยก็จะยิ่งสูงขึ้น
ในสถิติ การกำหนดลักษณะที่ถูกต้องของประชากรในแต่ละกรณีจะได้รับเฉพาะประเภทค่าเฉลี่ยที่แน่นอนเท่านั้น ในการกำหนดค่าเฉลี่ยประเภทนี้ จะใช้เกณฑ์ที่กำหนดคุณสมบัติของค่าเฉลี่ย: จากนั้นค่าเฉลี่ยจะเป็นลักษณะทั่วไปที่แท้จริงของประชากรตามแอตทริบิวต์ที่แตกต่างกันเมื่อเมื่อตัวแปรทั้งหมดถูกแทนที่ด้วยค่าเฉลี่ย ค่า ปริมาณรวมของแอตทริบิวต์ที่แตกต่างกันยังคงไม่เปลี่ยนแปลง นั่นคือประเภทที่ถูกต้องของค่าเฉลี่ยจะถูกกำหนดโดยวิธีการสร้างปริมาตรรวมของคุณลักษณะตัวแปร ดังนั้น ค่าเฉลี่ยเลขคณิตจะใช้เมื่อปริมาตรของคุณลักษณะตัวแปรถูกสร้างขึ้นเป็นผลรวมของตัวเลือกแต่ละตัว ค่าเฉลี่ยกำลังสอง - เมื่อปริมาตรของคุณลักษณะตัวแปรถูกสร้างขึ้นเป็นผลรวมของกำลังสอง ค่าเฉลี่ยฮาร์มอนิก - เป็นผลรวมของ ค่าซึ่งกันและกันของตัวเลือกแต่ละรายการ ค่าเฉลี่ยเรขาคณิต - เป็นผลิตภัณฑ์ของตัวเลือกแต่ละรายการ นอกจากค่าเฉลี่ยในสถิติแล้ว
ใช้ลักษณะเชิงพรรณนาของการแจกแจงคุณลักษณะตัวแปร (ค่าเฉลี่ยโครงสร้าง) โหมด (ตัวแปรที่พบบ่อยที่สุด) และค่ามัธยฐาน (ตัวแปรกลาง)



