قانون میانگین ها به زبان ساده مقادیر متوسط قانون ضعیف اعداد بزرگ
کلمات مربوط به اعداد بزرگ به تعداد تست ها اشاره دارد - تعداد زیادی از مقادیر یک متغیر تصادفی یا عمل تجمعی تعداد زیادی از متغیرهای تصادفی در نظر گرفته می شود. ماهیت این قانون به شرح زیر است: اگرچه نمی توان پیش بینی کرد که یک متغیر تصادفی منفرد در یک آزمایش منفرد چه مقداری خواهد گرفت، با این حال، نتیجه کل عمل تعداد زیادی از متغیرهای تصادفی مستقل ویژگی تصادفی خود را از دست می دهد و می تواند تقریباً قابل اطمینان (یعنی با احتمال بالا) پیش بینی شود. به عنوان مثال، نمی توان پیش بینی کرد که یک سکه روی کدام سمت می افتد. با این حال، اگر 2 تن سکه پرتاب کنید، با قطعیت می توان استدلال کرد که وزن سکه هایی که با نشان ملی سقوط کرده اند، 1 تن است.
اول از همه، نابرابری موسوم به چبیشف به قانون اعداد بزرگ اشاره دارد، که در یک آزمون جداگانه، احتمال پذیرش متغیر تصادفی مقداری را که از مقدار متوسط بیش از یک مقدار معین انحراف دارد، تخمین می زند.
نابرابری چبیشف. اجازه دهید ایکسیک متغیر تصادفی دلخواه است، a=M(X) ، آ D(ایکس) پراکندگی آن است. سپس
مثال. مقدار اسمی (یعنی مورد نیاز) قطر آستین ماشین کاری شده روی دستگاه است 5 میلی متر، و واریانس بیشتر از آن نیست 0.01 (این تلورانس دقت دستگاه است). این احتمال را تخمین بزنید که در ساخت یک بوش، انحراف قطر آن از اسمی کمتر از 0.5 میلی متر .
راه حل. اجازه دهید r.v. ایکس- قطر بوش ساخته شده. بر اساس شرایط، انتظار ریاضی آن برابر با قطر اسمی است (در صورت عدم وجود نقص سیستماتیک در راه اندازی دستگاه): a=M(X)=5 ، و واریانس D(X)≤0.01. اعمال نابرابری چبیشف برای ε = 0.5، ما گرفتیم:
بنابراین، احتمال چنین انحرافی بسیار زیاد است و بنابراین می توان نتیجه گرفت که در مورد ساخت تک تکه یک قطعه، انحراف قطر از قطر اسمی تقریباً به طور قطع تجاوز نخواهد کرد. 0.5 میلی متر .
اساساً انحراف معیار σ مشخص می کند میانگینانحراف یک متغیر تصادفی از مرکز آن (یعنی از انتظار ریاضی آن). زیرا آن را میانگینانحراف، سپس انحرافات بزرگ (تاکید بر o) در طول آزمایش امکان پذیر است. انحرافات بزرگ عملاً چقدر امکان پذیر است؟ هنگام مطالعه متغیرهای تصادفی با توزیع نرمال، قانون «سه سیگما» را استخراج کردیم: یک متغیر تصادفی با توزیع نرمال. ایکس در یک آزمونعملا از میانگین خود بیشتر از آن انحراف ندارد 3σ، جایی که σ= σ(X)انحراف استاندارد r.v است. ایکس. ما چنین قاعده ای را از این واقعیت استنباط کردیم که نابرابری را به دست آوردیم
 .
.
اجازه دهید اکنون احتمال آن را تخمین بزنیم دلخواهمتغیر تصادفی ایکسمقداری را بپذیرید که بیش از سه برابر انحراف استاندارد با میانگین تفاوت نداشته باشد. اعمال نابرابری چبیشف برای ε = 3σو با توجه به اینکه D(X)=σ 2 ، ما گرفتیم:
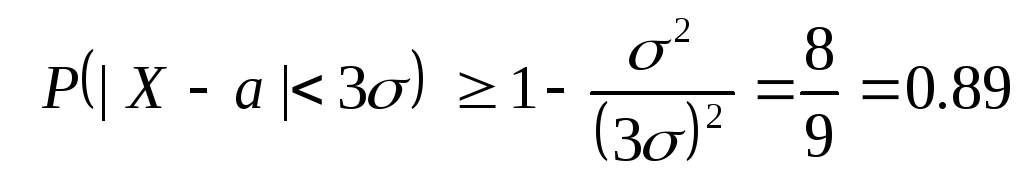 .
.
به این ترتیب، به طور کلیما می توانیم احتمال انحراف یک متغیر تصادفی از میانگین خود را با تعداد بیش از سه انحراف استاندارد تخمین بزنیم. 0.89 ، در حالی که برای توزیع نرمال می توان آن را با احتمال تضمین کرد 0.997 .
نابرابری چبیشف را می توان به سیستمی از متغیرهای تصادفی مستقل که به طور یکسان توزیع شده تعمیم داد.
تعمیم نابرابری چبیشف. اگر متغیرهای تصادفی مستقل باشند ایکس 1 ، ایکس 2 ، … ، ایکس n م(ایکس من )= آو پراکندگی ها D(ایکس من )= D، سپس
در n=1 این نابرابری به نابرابری چبیشف که در بالا فرموله شده است می رود.
از نابرابری چبیشف که برای حل مسائل مربوطه اهمیت مستقلی دارد، برای اثبات قضیه به اصطلاح چبیشف استفاده می شود. ابتدا ماهیت این قضیه را شرح می دهیم و سپس فرمول صوری آن را بیان می کنیم.
اجازه دهید ایکس 1
، ایکس 2
، … ، ایکس n- تعداد زیادی متغیر تصادفی مستقل با انتظارات ریاضی M(X 1
) = a 1
, … , M(X n ) = a n. اگرچه هر یک از آنها، در نتیجه آزمایش، می توانند مقداری دور از میانگین خود (یعنی انتظارات ریاضی) بگیرند، اما یک متغیر تصادفی  ، برابر با میانگین حسابی آنها، با احتمال زیاد مقداری نزدیک به یک عدد ثابت می گیرد.
، برابر با میانگین حسابی آنها، با احتمال زیاد مقداری نزدیک به یک عدد ثابت می گیرد.  (این میانگین تمام انتظارات ریاضی است). این به معنای زیر است. اجازه دهید، در نتیجه آزمون، متغیرهای تصادفی مستقل ایکس 1
، ایکس 2
، … ، ایکس n(تعداد زیادی وجود دارد!) مقادیر را بر این اساس گرفته اند ایکس 1
، ایکس 2
، … ، ایکس nبه ترتیب. سپس اگر خود این مقادیر دور از مقادیر متوسط متغیرهای تصادفی مربوطه باشند، مقدار متوسط آنها
(این میانگین تمام انتظارات ریاضی است). این به معنای زیر است. اجازه دهید، در نتیجه آزمون، متغیرهای تصادفی مستقل ایکس 1
، ایکس 2
، … ، ایکس n(تعداد زیادی وجود دارد!) مقادیر را بر این اساس گرفته اند ایکس 1
، ایکس 2
، … ، ایکس nبه ترتیب. سپس اگر خود این مقادیر دور از مقادیر متوسط متغیرهای تصادفی مربوطه باشند، مقدار متوسط آنها  به احتمال زیاد نزدیک است
به احتمال زیاد نزدیک است  . بنابراین، میانگین حسابی تعداد زیادی از متغیرهای تصادفی در حال حاضر ویژگی تصادفی خود را از دست می دهد و می تواند با دقت زیادی پیش بینی شود. این را می توان با این واقعیت توضیح داد که انحرافات تصادفی مقادیر ایکس مناز جانب آ منمی تواند علائم مختلفی داشته باشد و بنابراین در مجموع این انحرافات با احتمال زیاد جبران می شود.
. بنابراین، میانگین حسابی تعداد زیادی از متغیرهای تصادفی در حال حاضر ویژگی تصادفی خود را از دست می دهد و می تواند با دقت زیادی پیش بینی شود. این را می توان با این واقعیت توضیح داد که انحرافات تصادفی مقادیر ایکس مناز جانب آ منمی تواند علائم مختلفی داشته باشد و بنابراین در مجموع این انحرافات با احتمال زیاد جبران می شود.
ترما چبیشف (قانون اعداد بزرگبه شکل چبیشف). اجازه دهید ایکس 1 ، ایکس 2 ، … ، ایکس n … دنباله ای از متغیرهای تصادفی مستقل زوجی است که واریانس آنها به همان تعداد محدود می شود. سپس، مهم نیست که عدد ε چقدر کوچک است، احتمال نابرابری وجود دارد
خواهد بود خودسرانه نزدیک به وحدت اگر تعداد nمتغیرهای تصادفی به اندازه کافی بزرگ شوند. از نظر صوری، این بدان معناست که تحت شرایط قضیه
به این نوع همگرایی، همگرایی در احتمال گفته می شود و به صورت زیر نشان داده می شود:
بنابراین، قضیه چبیشف می گوید که اگر تعداد زیادی متغیر تصادفی مستقل به اندازه کافی زیاد باشد، میانگین حسابی آنها در یک آزمون تقریباً به طور قطع مقداری نزدیک به میانگین انتظارات ریاضی آنها خواهد داشت.
بیشتر اوقات، قضیه چبیشف در شرایطی اعمال می شود که متغیرهای تصادفی هستند ایکس 1 ، ایکس 2 ، … ، ایکس n … توزیع یکسانی دارند (یعنی قانون توزیع یکسان یا چگالی احتمال یکسان). در واقع، این فقط تعداد زیادی نمونه از همان متغیر تصادفی است.
نتیجه(نابرابری چبیشف تعمیم یافته). اگر متغیرهای تصادفی مستقل باشند ایکس 1 ، ایکس 2 ، … ، ایکس n … توزیع مشابهی با انتظارات ریاضی دارند م(ایکس من )= آو پراکندگی ها D(ایکس من )= D، سپس
 ، یعنی
، یعنی  .
.
اثبات از نابرابری تعمیم یافته چبیشف با عبور از حد به عنوان نتیجه می شود n→∞ .
یک بار دیگر متذکر می شویم که برابری های نوشته شده در بالا ارزش کمیت را تضمین نمی کند  تمایل دارد آدر n→∞. این مقدار هنوز یک متغیر تصادفی است و مقادیر فردی آن می تواند بسیار دور از آن باشد آ. اما احتمال چنین (دور از آ) مقادیر با افزایش nبه 0 تمایل دارد.
تمایل دارد آدر n→∞. این مقدار هنوز یک متغیر تصادفی است و مقادیر فردی آن می تواند بسیار دور از آن باشد آ. اما احتمال چنین (دور از آ) مقادیر با افزایش nبه 0 تمایل دارد.
اظهار نظر. نتیجه گیری نتیجه بدیهی است که در حالت کلی تر که متغیرهای تصادفی مستقل هستند نیز معتبر است ایکس 1 ، ایکس 2 ، … ، ایکس n … دارای توزیع متفاوت، اما انتظارات ریاضی یکسان (برابر آ) و واریانس های محدود در کل. این امکان پیشبینی دقت اندازهگیری یک کمیت خاص را فراهم میکند، حتی اگر این اندازهگیریها توسط ابزارهای مختلف انجام شود.
اجازه دهید کاربرد این نتیجه را برای اندازه گیری کمیت ها با جزئیات بیشتری در نظر بگیریم. بیایید از یک دستگاه استفاده کنیم nاندازه گیری های همان کمیت که مقدار واقعی آن است آو ما نمی دانیم نتایج چنین اندازه گیری ها ایکس 1
، ایکس 2
، … ، ایکس nممکن است به طور قابل توجهی با یکدیگر (و از مقدار واقعی) متفاوت باشد آ) به دلیل عوامل تصادفی مختلف (افت فشار، دما، ارتعاش تصادفی و غیره). r.v را در نظر بگیرید. ایکس- خواندن ابزار برای یک اندازه گیری واحد از یک کمیت، و همچنین مجموعه ای از r.v. ایکس 1
، ایکس 2
، … ، ایکس n- خواندن ابزار در اولین، دوم، ...، آخرین اندازه گیری. بنابراین، هر یک از مقادیر ایکس 1
، ایکس 2
، … ، ایکس n
فقط یکی از نمونه های r.v وجود دارد. ایکس، و بنابراین همه آنها توزیع یکسانی با r.v دارند. ایکس. از آنجایی که نتایج اندازه گیری مستقل از یکدیگر هستند، r.v. ایکس 1
، ایکس 2
، … ، ایکس nرا می توان مستقل در نظر گرفت. اگر دستگاه خطای سیستماتیک ندهد (به عنوان مثال، صفر روی ترازو "کوبیده نمی شود"، فنر کشیده نشده است، و غیره)، می توانیم فرض کنیم که انتظارات ریاضی وجود دارد. M(X) = a، و بنابراین M(X 1
) = ... = M(X n ) = الف. بنابراین، شرایط نتیجه فوق برآورده می شود، و بنابراین، به عنوان یک مقدار تقریبی مقدار آمیتوانیم «پیادهسازی» یک متغیر تصادفی را در نظر بگیریم  در آزمایش ما (شامل یک سری از nاندازه گیری ها)، یعنی
در آزمایش ما (شامل یک سری از nاندازه گیری ها)، یعنی
 .
.
با تعداد زیادی اندازه گیری، عملا قابل اعتماد است دقت خوبمحاسبات با استفاده از این فرمول این دلیل منطقی برای این اصل عملی است که با تعداد زیادی اندازه گیری، میانگین حسابی آنها عملاً تفاوت زیادی با مقدار واقعی کمیت اندازه گیری شده ندارد.
روش "نمونه گیری" که به طور گسترده در آمار ریاضی استفاده می شود، بر اساس قانون اعداد بزرگ است که امکان به دست آوردن ویژگی های عینی آن را با دقت قابل قبول از نمونه نسبتاً کوچکی از مقادیر یک متغیر تصادفی فراهم می کند. اما در بخش بعدی به این موضوع پرداخته خواهد شد.
مثال. در دستگاه اندازه گیری که اعوجاج سیستماتیک ایجاد نمی کند، کمیت معینی اندازه گیری می شود آیک بار (ارزش دریافت شده ایکس 1
، و سپس 99 بار دیگر (مقادیر ایکس 2
، … ، ایکس 100
). برای ارزش واقعی اندازه گیری آابتدا نتیجه اولین اندازه گیری را بگیرید  ، و سپس میانگین حسابی همه اندازه گیری ها
، و سپس میانگین حسابی همه اندازه گیری ها  . دقت اندازه گیری دستگاه به گونه ای است که انحراف معیار اندازه گیری σ بیش از 1 نباشد (زیرا واریانس D=σ
2
همچنین از 1 تجاوز نمی کند). برای هر یک از روش های اندازه گیری، احتمال اینکه خطای اندازه گیری بیشتر از 2 نباشد را تخمین بزنید.
. دقت اندازه گیری دستگاه به گونه ای است که انحراف معیار اندازه گیری σ بیش از 1 نباشد (زیرا واریانس D=σ
2
همچنین از 1 تجاوز نمی کند). برای هر یک از روش های اندازه گیری، احتمال اینکه خطای اندازه گیری بیشتر از 2 نباشد را تخمین بزنید.
راه حل. اجازه دهید r.v. ایکس- خواندن ابزار برای یک اندازه گیری واحد. سپس با شرط M(X)=a. برای پاسخ به این سؤالات، از نابرابری تعمیم یافته چبیشف استفاده می کنیم

برای ε =2
اول برای n=1
و سپس برای n=100
. در حالت اول می گیریم  ، و در دوم. بنابراین، مورد دوم عملاً دقت اندازهگیری داده شده را تضمین میکند، در حالی که مورد اول تردیدهای جدی را در این معنا ایجاد میکند.
، و در دوم. بنابراین، مورد دوم عملاً دقت اندازهگیری داده شده را تضمین میکند، در حالی که مورد اول تردیدهای جدی را در این معنا ایجاد میکند.
اجازه دهید عبارات فوق را برای متغیرهای تصادفی که در طرح برنولی ایجاد می شوند اعمال کنیم. اجازه دهید ماهیت این طرح را به یاد بیاوریم. بذار تولید بشه n آزمون های مستقل، که در هر یک از آنها برخی رویدادها ولیمی تواند با همان احتمال ظاهر شود آر، آ q=1–r(به این معنا، این احتمال رخداد مخالف است - نه وقوع یک رویداد ولی) . یک عدد خرج کنیم nچنین تست هایی متغیرهای تصادفی را در نظر بگیرید: ایکس 1 - تعداد وقوع رویداد ولیکه در 1 آزمون ام، ...، ایکس n- تعداد وقوع رویداد ولیکه در nآزمون هفتم همه معرفی شده r.v. می تواند ارزش ها را بگیرد 0 یا 1 (رویداد ولیممکن است در آزمایش ظاهر شود یا نه)، و مقدار 1 مشروط در هر آزمایش با احتمال پذیرفته شده است پ(احتمال وقوع یک رویداد ولیدر هر آزمون)، و مقدار 0 با احتمال q= 1 – پ. بنابراین، این مقادیر قوانین توزیع یکسانی دارند:
|
ایکس 1 | ||
|
ایکس n | ||
بنابراین، مقادیر متوسط این مقادیر و پراکندگی آنها نیز یکسان است: M(X 1 )=0 ∙ q+1 ∙ p= p، …، M(X n )= ص ; D(ایکس 1 )=(0 2 ∙ q+1 2 ∙ پ)− پ 2 = پ∙(1− پ)= پ ∙ س، …، D(ایکس n )= پ ∙ q . با جایگزینی این مقادیر به نابرابری چبیشف تعمیم یافته، به دست می آوریم
 .
.
واضح است که r.v. ایکس=ایکس 1 +…+X nتعداد وقوع رویداد است ولیدر همه nآزمایشات (همانطور که می گویند - "تعداد موفقیت ها" در nآزمایشات). اجازه دهید در nرویداد آزمایشی ولیظاهر شد در ک از آنها سپس نابرابری قبلی را می توان به صورت نوشتاری نوشت
 .
.
اما بزرگی  ، برابر با نسبت تعداد وقوع رویداد است ولیکه در nکارآزماییهای مستقل، به تعداد کل آزمایشها، که قبلاً نرخ رویداد نسبی نامیده میشد ولیکه در nتست ها بنابراین، یک نابرابری وجود دارد
، برابر با نسبت تعداد وقوع رویداد است ولیکه در nکارآزماییهای مستقل، به تعداد کل آزمایشها، که قبلاً نرخ رویداد نسبی نامیده میشد ولیکه در nتست ها بنابراین، یک نابرابری وجود دارد
 .
.
در حال گذراندن به حد مجاز در n→∞، می گیریم  ، یعنی
، یعنی  (بر اساس احتمال). این محتوای قانون اعداد بزرگ به شکل برنولی است. از این نتیجه می شود که برای تعداد کافی آزمایشات nانحرافات خودسرانه کوچک فرکانس نسبی
(بر اساس احتمال). این محتوای قانون اعداد بزرگ به شکل برنولی است. از این نتیجه می شود که برای تعداد کافی آزمایشات nانحرافات خودسرانه کوچک فرکانس نسبی  حوادث از احتمال آن آررویدادهای تقریباً مشخصی هستند و انحرافات بزرگ تقریباً غیرممکن است. نتیجه گیری در مورد چنین پایداری فرکانس های نسبی (که قبلاً به آن اشاره کردیم تجربیواقعیت) تعریف آماری معرفی شده قبلی از احتمال یک رویداد را به عنوان عددی که فرکانس نسبی یک رویداد حول آن نوسان می کند، توجیه می کند.
حوادث از احتمال آن آررویدادهای تقریباً مشخصی هستند و انحرافات بزرگ تقریباً غیرممکن است. نتیجه گیری در مورد چنین پایداری فرکانس های نسبی (که قبلاً به آن اشاره کردیم تجربیواقعیت) تعریف آماری معرفی شده قبلی از احتمال یک رویداد را به عنوان عددی که فرکانس نسبی یک رویداد حول آن نوسان می کند، توجیه می کند.
با توجه به اینکه بیان پ∙
q=
پ∙(1−
پ)=
پ−
پ 2
از فاصله تغییر تجاوز نمی کند  (به راحتی می توان این را با یافتن حداقل این تابع در این بخش تأیید کرد)، از نابرابری بالا
(به راحتی می توان این را با یافتن حداقل این تابع در این بخش تأیید کرد)، از نابرابری بالا  بدست آوردن آن آسان است
بدست آوردن آن آسان است
 ,
,
که در حل مسائل مربوطه استفاده می شود (یکی از آنها در زیر آورده خواهد شد).
مثال. سکه 1000 بار ورق خورد. احتمال اینکه انحراف فرکانس نسبی ظاهر نشان از احتمال آن کمتر از 0.1 باشد را تخمین بزنید.
راه حل. اعمال نابرابری  در پ=
q=1/2
,
n=1000
,
ε=0.1، ما گرفتیم .
در پ=
q=1/2
,
n=1000
,
ε=0.1، ما گرفتیم .
مثال. احتمال این که در شرایط مثال قبلی، عدد را تخمین بزنید کاز نشان های افتاده در محدوده خواهد بود 400 قبل از 600 .
راه حل. وضعیت 400<
ک<600
یعنی که 400/1000<
ک/
n<600/1000
، یعنی 0.4<
دبلیو n (آ)<0.6
یا  . همانطور که از مثال قبلی دیدیم، احتمال چنین رویدادی حداقل است 0.975
.
. همانطور که از مثال قبلی دیدیم، احتمال چنین رویدادی حداقل است 0.975
.
مثال. برای محاسبه احتمال وقوع یک رویداد ولی 1000 آزمایش انجام شد که در آن رویداد ولی 300 بار ظاهر شد احتمال متفاوت بودن فرکانس نسبی (برابر 300/1000=0.3) با احتمال واقعی را تخمین بزنید. آربیشتر از 0.1 نیست.
راه حل. با اعمال نابرابری فوق  برای n=1000، ε=0.1، دریافت می کنیم.
برای n=1000، ε=0.1، دریافت می کنیم.
قانون اعداد بزرگ
قانون اعداد بزرگدر نظریه احتمال بیان می کند که میانگین تجربی (میانگین حسابی) یک نمونه محدود به اندازه کافی بزرگ از یک توزیع ثابت نزدیک به میانگین نظری (انتظار) این توزیع است. بسته به نوع همگرایی، قانون ضعیفی از اعداد بزرگ وجود دارد، زمانی که همگرایی در احتمال اتفاق می افتد، و قانون قوی اعداد بزرگ، زمانی که همگرایی تقریباً در همه جا اتفاق می افتد.
همیشه تعداد زیادی آزمایش وجود خواهد داشت که با هر احتمال از پیش تعیین شده، فراوانی نسبی وقوع یک رویداد به طور دلخواه کمی با احتمال آن متفاوت است.
معنای کلی قانون اعداد بزرگ این است که عمل مشترک تعداد زیادی از عوامل تصادفی منجر به نتیجه ای می شود که تقریباً مستقل از شانس است.
روش های تخمین احتمال بر اساس تجزیه و تحلیل یک نمونه محدود بر اساس این ویژگی است. یک مثال خوب، پیش بینی نتایج انتخابات بر اساس نظرسنجی از یک نمونه از رای دهندگان است.
قانون ضعیف اعداد بزرگ
بگذارید یک دنباله نامتناهی (شمارش متوالی) از متغیرهای تصادفی توزیع شده و نامرتبط یکسان وجود داشته باشد که در فضای احتمال یکسان تعریف شده است. یعنی کوواریانس آنها. اجازه دهید . اجازه دهید میانگین نمونه عبارت های اول را نشان دهیم:
قانون قوی اعداد بزرگ
اجازه دهید یک دنباله نامتناهی از متغیرهای تصادفی مستقل با توزیع یکسان وجود داشته باشد که در همان فضای احتمال تعریف شده اند. اجازه دهید . اجازه دهید میانگین نمونه عبارت های اول را نشان دهیم:
.سپس تقریباً به طور قطع.
همچنین ببینید
ادبیات
- شیرایف A.N.احتمال، - M .: علم. 1989.
- چیستیاکوف V.P.درس تئوری احتمالات، - م.، 1361.
بنیاد ویکی مدیا 2010 .
- فیلمبرداری روسیه
- گرومکا، میخائیل استپانوویچ
ببینید "قانون اعداد بزرگ" در سایر لغت نامه ها چیست:
قانون اعداد بزرگ- (قانون اعداد بزرگ) در مواردی که رفتار تک تک اعضای جمعیت بسیار متمایز باشد، رفتار گروه به طور متوسط قابل پیش بینی تر از رفتار هر یک از اعضای آن است. روندی که در آن گروه ها ...... فرهنگ لغت اقتصادی
قانون اعداد بزرگ- قانون اعداد بزرگ را ببینید. آنتی نازی. دایره المعارف جامعه شناسی، 2009 ... دایره المعارف جامعه شناسی
قانون اعداد بزرگ- این اصل که بر اساس آن الگوهای کمی ذاتی در پدیده های اجتماعی توده ای با تعداد کافی مشاهدات به وضوح آشکار می شود. پدیده های منفرد بیشتر در معرض تأثیرات تصادفی و ... هستند. واژه نامه اصطلاحات تجاری
قانون اعداد بزرگ- ادعا می کند که با احتمال نزدیک به یک، میانگین حسابی تعداد زیادی از متغیرهای تصادفی تقریباً یکسان با یک ثابت برابر با میانگین حسابی انتظارات ریاضی این متغیرها تفاوت کمی خواهد داشت. تفاوت… … دایره المعارف زمین شناسی
قانون اعداد بزرگ- - [Ya.N. Luginsky، M.S. Fezi Zhilinskaya، Yu.S. Kabirov. انگلیسی روسی فرهنگ لغت مهندسی برق و صنعت برق، مسکو، 1999] مباحث مهندسی برق، مفاهیم اساسی EN قانون متوسط قانون اعداد بزرگ ... کتابچه راهنمای مترجم فنی
قانون اعداد بزرگ- didžiųjų skaičių dėsnis statusas T sritis fizika atitikmenys: انگلیسی. قانون اعداد بزرگ vok Gesetz der großen Zahlen، n rus. قانون اعداد بزرگ، m pranc. loi des grands nombres, f … Fizikos Terminų žodynas
قانون اعداد بزرگ- یک اصل کلی که به موجب آن عمل ترکیبی عوامل تصادفی، تحت شرایط بسیار کلی معین، به نتیجه ای تقریبا مستقل از شانس منجر می شود. همگرایی فراوانی وقوع یک رویداد تصادفی با احتمال آن با افزایش تعداد ... ... دایره المعارف جامعه شناسی روسیه
قانون اعداد بزرگ- قانونی که بیان می کند که عمل تجمعی تعداد زیادی از عوامل تصادفی، تحت شرایط بسیار کلی معین، به نتیجه ای تقریباً مستقل از شانس منجر می شود ... جامعه شناسی: فرهنگ لغت
قانون اعداد بزرگ- قانون آماری بیانگر رابطه شاخص ها (پارامترهای) آماری نمونه و جامعه عمومی. مقادیر واقعی شاخص های آماری به دست آمده از یک نمونه خاص همیشه با به اصطلاح متفاوت است. نظری ... ... جامعه شناسی: دایره المعارف
قانون اعداد بزرگ- این اصل که فراوانی زیان های مالی از نوع خاصی را می توان با دقت بالایی پیش بینی کرد زمانی که تعداد زیادی از زیان از انواع مشابه وجود دارد ... فرهنگ دایره المعارف اقتصاد و حقوق
کتاب ها
- مجموعه ای از میز. ریاضی. نظریه احتمالات و آمار ریاضی. 6 جدول + روش شناسی، . جداول بر روی مقوای پلی گرافی ضخیم در ابعاد 680*980 میلی متر چاپ شده است. این کیت شامل بروشوری با توصیه های روش شناختی برای معلمان است. آلبوم آموزشی 6 برگه. تصادفی…
راز فروشندگان موفق چیست؟ اگر بهترین فروشندگان هر شرکتی را تماشا کنید، متوجه خواهید شد که آنها در یک چیز مشترک هستند. هر یک از آنها با افراد بیشتری ملاقات می کنند و ارائه های بیشتری نسبت به فروشندگان کمتر موفق ارائه می دهند. این افراد میدانند که فروش یک بازی اعداد است، و هر چه به افراد بیشتری درباره محصولات یا خدمات خود بگویند، معاملات بیشتری بسته میشوند، همین. آنها درک می کنند که اگر نه تنها با آن تعداد معدودی که قطعاً به آنها بله می گویند، بلکه با کسانی که علاقه آنها به پیشنهاد آنها چندان زیاد نیست ارتباط برقرار کنند، آنگاه قانون میانگین ها به نفع آنها عمل خواهد کرد.
درآمد شما به تعداد فروش بستگی دارد، اما در عین حال، با تعداد ارائه هایی که انجام می دهید نسبت مستقیم خواهد داشت. هنگامی که قانون میانگین ها را درک کردید و شروع به اجرای آن کردید، اضطراب مرتبط با شروع یک تجارت جدید یا کار در یک زمینه جدید شروع به کاهش می کند. و در نتیجه، احساس کنترل و اعتماد به توانایی آنها برای کسب درآمد شروع به رشد خواهد کرد. اگر فقط ارائه کنید و مهارت های خود را در این فرآیند تقویت کنید، معاملاتی وجود خواهد داشت.
به جای اینکه به تعداد معاملات فکر کنید، به تعداد ارائه ها فکر کنید. معنی ندارد که صبح از خواب بیدار شوید یا عصر به خانه بیایید و فکر کنید چه کسی محصول شما را خواهد خرید. در عوض، بهتر است هر روز برای چند تماس برنامه ریزی کنید. و سپس، مهم نیست که چه - همه آن تماس ها را انجام دهید! این رویکرد کار شما را آسان تر می کند - زیرا این یک هدف ساده و خاص است. اگر می دانید که هدف بسیار مشخص و دست یافتنی در پیش دارید، برقراری تعداد تماس های برنامه ریزی شده برای شما آسان تر خواهد شد. اگر در طول این فرآیند چند بار «بله» بشنوید، خیلی بهتر است!
و اگر "نه"، پس از ظهر احساس می کنید که صادقانه هر کاری را که می توانستید انجام دادید و از افکاری که در مورد اینکه چقدر پول به دست آورده اید یا چند شریک در یک روز به دست آورده اید عذاب ندهید.
فرض کنید در شرکت یا کسب و کار شما، یک فروشنده به طور متوسط هر چهار ارائه یک معامله را می بندد. حالا تصور کنید که در حال کشیدن کارت از روی یک عرشه هستید. هر کارت از سه کت و شلوار - بیل، الماس و چماق - ارائه ای است که در آن شما به طور حرفه ای یک محصول، خدمات یا فرصت را ارائه می کنید. شما این کار را به بهترین شکل ممکن انجام می دهید، اما هنوز معامله را نمی بندید. و هر کارت قلب معامله ای است که به شما امکان می دهد پول دریافت کنید یا یک همراه جدید به دست آورید.
در چنین شرایطی، آیا نمی خواهید تا جایی که ممکن است از روی عرشه کارت بکشید؟ فرض کنید به شما پیشنهاد می شود هر تعداد کارت را که می خواهید بکشید، در حالی که هر بار که یک کارت قلب می کشید، به شما پول می پردازد یا یک همراه جدید را پیشنهاد می کند. شما با اشتیاق شروع به کشیدن کارت خواهید کرد و به سختی متوجه خواهید شد که کارت به تازگی چه لباسی بیرون کشیده است.
می دانید که سیزده قلب در یک عرشه پنجاه و دو کارتی وجود دارد. و در دو عرشه - بیست و شش کارت قلب و غیره. آیا با کشیدن بیل، الماس یا چماق ناامید خواهید شد؟ البته که نه! شما فقط فکر می کنید که هر "دشیزه" شما را نزدیک تر می کند - به چه چیزی؟ به کارت دلها!
اما میدونی چیه؟ قبلاً این پیشنهاد به شما داده شده است. شما در موقعیت منحصر به فردی هستید که می توانید هر چقدر که می خواهید درآمد کسب کنید و هر تعداد کارت قلبی که می خواهید در زندگی خود بکشید بکشید. و اگر فقط با وجدان "کارت بکشید"، مهارت های خود را بهبود ببخشید و کمی بیل، الماس و چماق را تحمل کنید، آنگاه یک فروشنده عالی خواهید شد و موفق خواهید شد.
یکی از چیزهایی که فروش را بسیار سرگرم کننده می کند این است که هر بار که عرشه را به هم می زنید، کارت ها به گونه ای متفاوت به هم می ریزند. گاهی اوقات همه قلب ها به ابتدای عرشه ختم می شوند و پس از یک رگبار موفقیت آمیز (زمانی که از قبل به نظر می رسد که هرگز نخواهیم شکست!) ما منتظر یک ردیف طولانی از کارت های یک لباس متفاوت هستیم. و بار دیگر، برای رسیدن به قلب اول، باید از بی نهایت بیل، چماق و تنبور عبور کرد. و گاهی اوقات کارت های لباس های مختلف به نوبه خود به شدت بیرون می افتند. اما در هر صورت، در هر دسته از پنجاه و دو کارت، به ترتیبی، همیشه سیزده قلب وجود دارد. فقط کارت ها را بیرون بکشید تا زمانی که آنها را پیدا کنید.
از: لیلیا،
قانون اعداد بزرگدر نظریه احتمال بیان می کند که میانگین تجربی (میانگین حسابی) یک نمونه محدود به اندازه کافی بزرگ از یک توزیع ثابت نزدیک به میانگین نظری (انتظار) این توزیع است. بسته به نوع همگرایی، می توان بین قانون ضعیف اعداد بزرگ، زمانی که همگرایی در احتمال وجود دارد، و قانون قوی اعداد بزرگ، زمانی که تقریباً در همه جا همگرایی وجود دارد، تمایز قائل شد.
همیشه تعداد محدودی آزمایش وجود دارد که با هر احتمال معین، کمتر از 1 فراوانی نسبی وقوع یک رویداد به طور دلخواه کمی با احتمال آن متفاوت است.
معنی کلی قانون اعداد بزرگ: عمل مشترک تعداد زیادی از عوامل تصادفی یکسان و مستقل منجر به نتیجه ای می شود که در حد، به شانس بستگی ندارد.
روش های تخمین احتمال بر اساس تجزیه و تحلیل یک نمونه محدود بر اساس این ویژگی است. یک مثال خوب، پیش بینی نتایج انتخابات بر اساس نظرسنجی از یک نمونه از رای دهندگان است.
یوتیوب دایره المعارفی
1 / 5
✪ قانون اعداد بزرگ
✪ 07 - نظریه احتمال. قانون اعداد بزرگ
✪ 42 قانون اعداد بزرگ
✪ 1 - قانون اعداد بزرگ چبیشف
✪ کلاس 11، درس 25، منحنی گاوسی. قانون اعداد بزرگ
زیرنویس
بیایید نگاهی به قانون اعداد بزرگ بیندازیم که شاید شهودی ترین قانون در ریاضیات و نظریه احتمالات باشد. و چون در مورد خیلی چیزها صدق می کند، گاهی اوقات مورد استفاده و سوء تفاهم قرار می گیرد. اجازه دهید ابتدا تعریفی برای دقت ارائه کنم و سپس در مورد شهود صحبت خواهیم کرد. بیایید یک متغیر تصادفی، مثلاً X را در نظر بگیریم. فرض کنیم انتظارات ریاضی یا میانگین جمعیت آن را میدانیم. قانون اعداد بزرگ به سادگی می گوید که اگر n-امین تعداد مشاهدات یک متغیر تصادفی را مثال بزنیم و تعداد همه آن مشاهدات را میانگین بگیریم... بیایید یک متغیر را در نظر بگیریم. بیایید آن را X با یک زیرنویس n و یک خط تیره در بالا بنامیم. این میانگین حسابی nامین تعداد مشاهدات متغیر تصادفی ما است. در اینجا اولین مشاهده من است. من آزمایش را یک بار انجام میدهم و این مشاهده را انجام میدهم، سپس دوباره انجام میدهم و این مشاهده را انجام میدهم، دوباره انجام میدهم و این را میگیرم. من این آزمایش را n بار اجرا می کنم و سپس بر تعداد مشاهداتم تقسیم می کنم. در اینجا میانگین نمونه من است. در اینجا میانگین تمام مشاهداتی که انجام دادم است. قانون اعداد بزرگ به ما می گوید که میانگین نمونه من به میانگین متغیر تصادفی نزدیک می شود. یا می توانم بنویسم که میانگین نمونه من به میانگین جمعیت برای عدد n که به بی نهایت می رسد نزدیک می شود. من تمایز واضحی بین "تقریبی" و "همگرایی" قائل نمیشوم، اما امیدوارم به طور شهودی متوجه شده باشید که اگر من یک نمونه نسبتاً بزرگ در اینجا بگیرم، ارزش مورد انتظار را برای کل جمعیت به دست میآورم. فکر میکنم بیشتر شما بهطور شهودی میدانید که اگر آزمایشهای کافی را با نمونههای بزرگ انجام دهم، در نهایت تستها با در نظر گرفتن انتظارات ریاضی، احتمال و همه اینها، مقادیر مورد انتظارم را به من میدهند. اما من فکر می کنم اغلب مشخص نیست که چرا این اتفاق می افتد. و قبل از اینکه توضیح دهم چرا اینطور است، اجازه دهید یک مثال عینی برای شما بیاورم. قانون اعداد بزرگ به ما می گوید که ... فرض کنید یک متغیر تصادفی X داریم. این عدد برابر است با تعداد سر در 100 پرتاب سکه صحیح. اول از همه، ما انتظارات ریاضی این متغیر تصادفی را می دانیم. این تعداد پرتاب سکه یا چالش ضربدر شانس موفقیت هر چالش است. پس برابر با 50 است. یعنی قانون اعداد بزرگ می گوید اگر نمونه برداریم یا این آزمایش ها را میانگین بگیرم، می گیرم. .. اولین بار که تست میزنم یک سکه رو 100 بار میزنم یا یک جعبه صد سکه برمیدارم تکونش میدم و بعد میشمارم چند سرم میاد و مثلا عدد 55 رو میگیرم این میشه X1. سپس جعبه را دوباره تکان میدهم و عدد 65 را میگیرم. سپس دوباره - و 45 میگیرم. و این کار را n بار انجام میدهم و سپس آن را بر تعداد آزمایشها تقسیم میکنم. قانون اعداد بزرگ به ما می گوید که این میانگین (میانگین تمام مشاهدات من) به 50 گرایش خواهد داشت در حالی که n به بی نهایت تمایل دارد. اکنون می خواهم کمی در مورد اینکه چرا این اتفاق می افتد صحبت کنم. خیلی ها بر این باورند که اگر بعد از 100 آزمایش، نتیجه من بالاتر از حد متوسط باشد، طبق قوانین احتمال باید سرم کم و بیش باشد تا به اصطلاح بتوانم تفاوت را جبران کنم. این دقیقاً چیزی نیست که اتفاق بیفتد. این اغلب به عنوان "اشتباه قمارباز" شناخته می شود. بگذارید تفاوت را به شما نشان دهم. از مثال زیر استفاده خواهم کرد. بگذارید یک نمودار بکشم. بیایید رنگ را تغییر دهیم. این n است، محور x من n است. این تعداد تست هایی است که من انجام خواهم داد. و محور y من میانگین نمونه خواهد بود. می دانیم که میانگین این متغیر دلخواه 50 است. بذار اینو بکشم این 50 است. اجازه دهید به مثال خود برگردیم. اگر n باشد ... در اولین آزمون من 55 گرفتم که میانگین من است. من فقط یک نقطه ورود اطلاعات دارم. سپس بعد از دو آزمایش، من 65 میگیرم. بنابراین میانگین من 65+55 تقسیم بر 2 خواهد شد. این 60 است. و میانگین من کمی بالا رفت. بعد من 45 گرفتم که دوباره میانگین حسابی ام را پایین آورد. من 45 را روی نمودار ترسیم نمی کنم. حالا باید همه آن را میانگین بگیرم. 45+65 برابر است با چیست؟ اجازه دهید این مقدار را برای نشان دادن نقطه محاسبه کنم. یعنی 165 تقسیم بر 3. یعنی 53. نه، 55. بنابراین میانگین دوباره به 55 کاهش می یابد. ما می توانیم این آزمایشات را ادامه دهیم. بعد از اینکه ما سه آزمایش را انجام دادیم و به این میانگین رسیدیم، بسیاری از مردم فکر می کنند که خدایان احتمال آن را طوری می کنند که در آینده سرهای کمتری داشته باشیم، چند آزمایش بعدی برای کاهش میانگین کمتر خواهد بود. اما همیشه اینطور نیست. در آینده، احتمال همیشه ثابت می ماند. احتمال اینکه من سرها را بچرخانم همیشه 50٪ خواهد بود. نه این که در ابتدا تعداد معینی سر، بیشتر از آنچه انتظار دارم، به دست میآورم، و سپس ناگهان دمها میریزند. این "اشتباه بازیکن" است. اگر تعداد نامتناسبی سر به دست می آورید، به این معنی نیست که در یک نقطه شروع به سقوط تعداد نامتناسبی از دم خواهید کرد. این کاملا درست نیست. قانون اعداد بزرگ به ما می گوید که مهم نیست. فرض کنید، پس از تعداد محدودی آزمایش، میانگین شما... احتمال این بسیار کم است، اما، با این وجود... فرض کنید میانگین شما به این علامت برسد - 70. شما فکر می کنید، "وای، ما خیلی فراتر از حد انتظار رفتیم." اما قانون اعداد بزرگ می گوید مهم نیست که چند تست انجام می دهیم. ما هنوز بی نهایت آزمایش در پیش داریم. انتظار ریاضی از این تعداد بی نهایت آزمایش، به خصوص در شرایطی مانند این، به شرح زیر خواهد بود. وقتی به یک عدد متناهی می رسید که مقدار زیادی را بیان می کند، یک عدد نامتناهی که با آن همگرا می شود دوباره به مقدار مورد انتظار منجر می شود. این، البته، یک تفسیر بسیار سست است، اما این چیزی است که قانون اعداد بزرگ به ما می گوید. مهم است. او به ما نمی گوید که اگر سرهای زیادی داشته باشیم، به نوعی شانس دم گرفتن برای جبران افزایش می یابد. این قانون به ما می گوید که تا زمانی که شما هنوز تعداد نامحدودی آزمایش در پیش دارید، مهم نیست که با تعداد محدود آزمایش چه نتیجه ای حاصل می شود. و اگر به اندازه کافی از آنها استفاده کنید، دوباره به انتظارات باز خواهید گشت. این نکته ی مهمی است. در مورد آن فکر کنید. اما در عمل با قرعه کشی ها و کازینو ها روزانه از این استفاده نمی شود، اگرچه معلوم است که اگر تست کافی انجام دهید ... حتی می توانیم آن را محاسبه کنیم ... احتمال اینکه به طور جدی از هنجار خارج شویم چقدر است؟ اما کازینوها و بخت آزمایی ها هر روز بر این اصل کار می کنند که اگر تعداد افراد کافی را، البته در مدت زمان کوتاه، با یک نمونه کوچک بگیرید، آن وقت چند نفر به جک پات خواهند رسید. اما در درازمدت، کازینو همیشه از پارامترهای بازی هایی که شما را به بازی دعوت می کند، سود می برد. این یک اصل احتمال مهم است که شهودی است. اگرچه گاهی اوقات، وقتی به طور رسمی با متغیرهای تصادفی برای شما توضیح داده می شود، همه چیز کمی گیج کننده به نظر می رسد. تمام این قانون می گوید که هر چه تعداد نمونه ها بیشتر باشد، میانگین حسابی آن نمونه ها بیشتر به میانگین واقعی همگرا می شود. و برای دقیق تر، میانگین حسابی نمونه شما با انتظارات ریاضی یک متغیر تصادفی همگرا می شود. همین. شما را در ویدیوی بعدی می بینیم!
قانون ضعیف اعداد بزرگ
قانون ضعیف اعداد بزرگ را به نام ژاکوب-برنولی که در سال 1713 آن را اثبات کرد، قضیه برنولی نیز نامیده می شود.
بگذارید یک دنباله نامتناهی (شمارش متوالی) از متغیرهای تصادفی توزیع شده و نامرتبط یکسان وجود داشته باشد. یعنی کوواریانس آنها c o v (X i , X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). اجازه دهید . با میانگین نمونه اول مشخص کنید n (\displaystyle n)اعضا:
.
سپس X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P))\mu).
یعنی برای هر مثبت ε (\displaystyle \varepsilon)
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}قانون قوی اعداد بزرگ
بگذارید یک دنباله نامتناهی از متغیرهای تصادفی مستقل با توزیع یکسان وجود داشته باشد ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty ))در یک فضای احتمال تعریف شده است (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F))،\mathbb (P))). اجازه دهید E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N)). با نشان دادن X¯n (\displaystyle (\bar(X))_(n))میانگین نمونه اول n (\displaystyle n)اعضا:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i)،\;n\in \mathbb (N)).سپس X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu)تقریبا همیشه.
Pr (lim n ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty)(\bar (X))_(n)=\mu \ درست) = 1.) .مانند هر قانون ریاضی، قانون اعداد بزرگ را فقط می توان در دنیای واقعی تحت مفروضات شناخته شده ای اعمال کرد، که فقط با درجه خاصی از دقت قابل انجام است. بنابراین، به عنوان مثال، شرایط آزمون های متوالی اغلب نمی تواند به طور نامحدود و با دقت مطلق حفظ شود. علاوه بر این، قانون اعداد بزرگ فقط از آن صحبت می کند غیر احتمالیانحراف معنی دار مقدار میانگین از انتظارات ریاضی.
مقدار میانگین عمومی ترین شاخص در آمار است. این به دلیل این واقعیت است که می توان از آن برای توصیف جمعیت با توجه به یک ویژگی کمی متفاوت استفاده کرد. به عنوان مثال، برای مقایسه دستمزد کارگران دو شرکت، دستمزد دو کارگر خاص را نمی توان در نظر گرفت، زیرا به عنوان یک شاخص متغیر عمل می کند. همچنین، کل مبلغ دستمزد پرداخت شده در شرکت ها را نمی توان گرفت، زیرا به تعداد کارکنان بستگی دارد. اگر مجموع دستمزد هر بنگاه را بر تعداد کارکنان تقسیم کنیم، میتوانیم آنها را با هم مقایسه کنیم و مشخص کنیم کدام بنگاه متوسط دستمزد بیشتری دارد.
به عبارت دیگر، دستمزد جمعیت مورد مطالعه کارگران یک مشخصه تعمیم یافته در مقدار متوسط دریافت می کند. کلی و معمولی که مشخصه کلیت کارگران در رابطه با صفت مورد مطالعه است را بیان می کند. در این مقدار، اندازه کلی این ویژگی را نشان می دهد که برای واحدهای جمعیت مقدار متفاوتی دارد.
تعیین مقدار متوسط مقدار متوسط در آمار یک مشخصه تعمیم یافته مجموعه ای از پدیده های مشابه بر اساس برخی ویژگی های کمی متفاوت است. مقدار متوسط سطح این ویژگی را نشان می دهد که مربوط به واحد جمعیت است. با کمک مقدار متوسط، می توان دانه های مختلف را با توجه به ویژگی های مختلف (درآمد سرانه، عملکرد محصول، هزینه های تولید در شرکت های مختلف) با یکدیگر مقایسه کرد.
مقدار متوسط همیشه تغییرات کمی صفتی را که ما جمعیت مورد مطالعه را مشخص میکنیم تعمیم میدهد و به طور یکسان در همه واحدهای جامعه ذاتی است. این بدان معنی است که پشت هر مقدار متوسط، همیشه یک سری توزیع از واحدهای جمعیت بر اساس برخی ویژگیهای متفاوت وجود دارد، یعنی. سری تغییرات از این نظر، مقدار متوسط اساساً با مقادیر نسبی و به ویژه با شاخصهای شدت متفاوت است. شاخص شدت نسبت حجم دو مجموع مختلف (مثلاً تولید ناخالص داخلی سرانه) است، در حالی که شاخص متوسط، ویژگی های عناصر کل را با توجه به یکی از ویژگی ها (مثلاً میانگین) تعمیم می دهد. دستمزد یک کارگر).
مقدار میانگین و قانون اعداد بزرگ.در تغییر شاخص های میانگین، یک روند کلی آشکار می شود که تحت تأثیر آن روند توسعه پدیده ها به طور کلی شکل می گیرد، در حالی که در موارد فردی ممکن است این روند به وضوح آشکار نشود. مهم است که میانگین ها بر اساس تعمیم گسترده واقعیات باشد. تنها تحت این شرایط آنها روند کلی زیربنای فرآیند را به عنوان یک کل آشکار می کنند.
ماهیت قانون اعداد بزرگ و اهمیت آن برای میانگین ها، با افزایش تعداد مشاهدات، بیشتر و کامل تر می شود. یعنی قانون اعداد بزرگ شرایطی را ایجاد می کند تا سطح معمولی از یک ویژگی متغیر در مقدار متوسط تحت شرایط مکانی و زمانی خاص ظاهر شود. ارزش این سطح با ماهیت این پدیده تعیین می شود.
انواع میانگین هامقادیر میانگین مورد استفاده در آمار متعلق به کلاس توانی است که فرمول کلی آن به شرح زیر است:
جایی که x میانگین توان است.
X - تغییر مقادیر ویژگی (گزینه ها)
- گزینه شماره
توان میانگین;
علامت جمع.
برای مقادیر مختلف توان میانگین، انواع مختلفی از میانگین به دست می آید:
میانگین حسابی؛
میانگین مربع؛
مکعب متوسط؛
هارمونیک متوسط؛
میانگین هندسی.
هنگام استفاده از آمار منبع یکسان، انواع مختلف میانگین معانی متفاوتی دارند. در عین حال، هر چه توان میانگین بزرگتر باشد، مقدار آن بیشتر است.
در آمار، توصیف صحیح جمعیت در هر مورد جداگانه تنها با یک نوع کاملاً مشخص از مقادیر میانگین ارائه می شود. برای تعیین این نوع مقدار متوسط، از معیاری استفاده میشود که ویژگیهای میانگین را تعیین میکند: مقدار متوسط تنها در آن صورت یک مشخصه تعمیمدهنده واقعی جامعه با توجه به ویژگی متغیر خواهد بود، زمانی که همه متغیرها با میانگین جایگزین شوند. مقدار، حجم کل ویژگی متغیر بدون تغییر باقی می ماند. یعنی نوع صحیح میانگین با نحوه تشکیل حجم کل ویژگی متغیر مشخص می شود. بنابراین، میانگین حسابی زمانی استفاده میشود که حجم ویژگی متغیر بهعنوان مجموع گزینههای جداگانه تشکیل شود، میانگین مربع - وقتی حجم ویژگی متغیر به صورت مجموع مربعها تشکیل میشود، میانگین هارمونیک - به عنوان مجموع مقادیر متقابل گزینه های فردی، میانگین هندسی - به عنوان محصول گزینه های فردی. علاوه بر مقادیر متوسط در آمار
از ویژگی های توصیفی توزیع یک ویژگی متغیر (میانگین های ساختاری)، حالت (متداول ترین نوع) و میانه (نوع متوسط) استفاده می شود.



