Lagen om medeltal i enkla termer. Genomsnittliga värden. Svag lag av stora tal
Orden om stora tal hänvisar till antalet tester - ett stort antal värden av en slumpvariabel eller den kumulativa verkan av ett stort antal slumpvariabler beaktas. Kärnan i denna lag är som följer: även om det är omöjligt att förutsäga vilket värde en enskild slumpvariabel kommer att ta i ett enda experiment, förlorar dock det totala resultatet av verkan av ett stort antal oberoende slumpvariabler sin slumpmässiga karaktär och kan förutsägas nästan tillförlitligt (d.v.s. med hög sannolikhet). Det är till exempel omöjligt att förutse vilken sida ett mynt kommer att falla på. Men om man slänger 2 ton mynt så kan man med stor säkerhet hävda att vikten på de mynt som föll med vapenskölden upp är 1 ton.
Först och främst hänvisar den så kallade Chebyshev-olikheten till lagen om stora siffror, som i ett separat test uppskattar sannolikheten för att en slumpvariabel accepterar ett värde som avviker från medelvärdet med högst ett givet värde.
Chebyshevs ojämlikhet. Låta Xär en godtycklig slumpvariabel, a=M(X) , a D(X) är dess spridning. Sedan
Exempel. Det nominella (d.v.s. erforderliga) värdet för diametern på hylsan som bearbetas på maskinen är 5 mm, och variansen är inte mer än 0.01 (detta är maskinens noggrannhetstolerans). Uppskatta sannolikheten att vid tillverkningen av en bussning kommer dess diameters avvikelse från den nominella att vara mindre än 0,5 mm .
Lösning. Låt r.v. X- diametern på den tillverkade bussningen. Tillståndet är att dess matematiska förväntan är lika med den nominella diametern (om det inte finns något systematiskt fel i installationen av maskinen): a=M(X)=5 , och variansen D(X) < 0,01. Att tillämpa Chebyshev ojämlikhet för e = 0,5, vi får:
Således är sannolikheten för en sådan avvikelse ganska hög, och därför kan vi dra slutsatsen att i fallet med en enda tillverkning av en del kommer diameterns avvikelse från den nominella nästan säkert inte att överstiga 0,5 mm .
I grund och botten standardavvikelsen σ kännetecknar medel avvikelse för en slumpvariabel från dess centrum (dvs. från dess matematiska förväntan). Därför det medel avvikelse, då är stora avvikelser (betoning på o) möjliga vid testning. Hur stora avvikelser är praktiskt möjliga? När vi studerade normalfördelade slumpvariabler härledde vi "tre sigma"-regeln: en normalfördelad slumpvariabel X i ett enda test praktiskt taget inte avviker från sitt genomsnitt längre än 3σ, var σ= σ(X)är standardavvikelsen för r.v. X. Vi härledde en sådan regel från det faktum att vi fick ojämlikheten
 .
.
Låt oss nu uppskatta sannolikheten för slumpmässig slumpvariabel X acceptera ett värde som inte skiljer sig från medelvärdet med mer än tre gånger standardavvikelsen. Att tillämpa Chebyshev ojämlikhet för ε = 3σ och givet det D(X)=σ 2 , vi får:
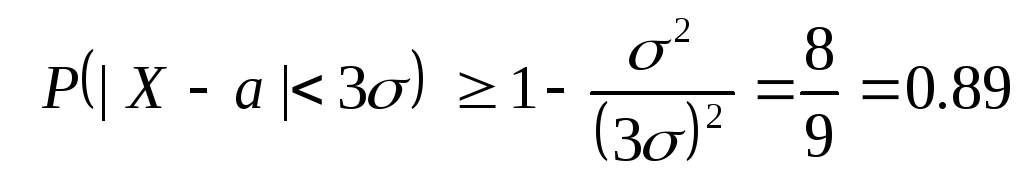 .
.
På det här sättet, i allmänhet vi kan uppskatta sannolikheten för att en stokastisk variabel avviker från sitt medelvärde med högst tre standardavvikelser med antalet 0.89 , medan det för en normalfördelning kan garanteras med sannolikhet 0.997 .
Chebyshevs ojämlikhet kan generaliseras till ett system av oberoende identiskt fördelade slumpvariabler.
Generaliserade Chebyshevs ojämlikhet. Om oberoende slumpvariabler X 1 , X 2 , … , X n M(X i )= a och dispersioner D(X i )= D, då
På n=1 denna ojämlikhet går över i Chebyshev-ojämlikheten formulerad ovan.
Chebyshev-ojämlikheten, som har oberoende betydelse för att lösa motsvarande problem, används för att bevisa den så kallade Chebyshev-satsen. Vi beskriver först kärnan i denna sats och ger sedan dess formella formulering.
Låta X 1
, X 2
, … , X n– ett stort antal oberoende slumpvariabler med matematiska förväntningar M(X 1
)=a 1
, … , M(X n )=a n. Även om var och en av dem, som ett resultat av experimentet, kan ta ett värde långt från sitt genomsnitt (d.v.s. matematiska förväntningar), men en slumpvariabel  , lika med deras aritmetiska medelvärde, kommer med hög sannolikhet att ta ett värde nära ett fast tal
, lika med deras aritmetiska medelvärde, kommer med hög sannolikhet att ta ett värde nära ett fast tal  (detta är genomsnittet av alla matematiska förväntningar). Det betyder följande. Låt, som ett resultat av testet, oberoende slumpvariabler X 1
, X 2
, … , X n(det finns många av dem!) har tagit värderingarna i enlighet med det X 1
, X 2
, … , X n respektive. Sedan om dessa värden själva kan visa sig vara långt ifrån medelvärdena för motsvarande slumpvariabler, deras medelvärde
(detta är genomsnittet av alla matematiska förväntningar). Det betyder följande. Låt, som ett resultat av testet, oberoende slumpvariabler X 1
, X 2
, … , X n(det finns många av dem!) har tagit värderingarna i enlighet med det X 1
, X 2
, … , X n respektive. Sedan om dessa värden själva kan visa sig vara långt ifrån medelvärdena för motsvarande slumpvariabler, deras medelvärde  sannolikt ligger nära
sannolikt ligger nära  . Det aritmetiska medelvärdet av ett stort antal slumpmässiga variabler förlorar alltså redan sin slumpmässiga karaktär och kan förutsägas med stor noggrannhet. Detta kan förklaras av det faktum att slumpmässiga avvikelser av värdena X i från a i kan ha olika tecken, och därför kompenseras dessa avvikelser totalt sett med stor sannolikhet.
. Det aritmetiska medelvärdet av ett stort antal slumpmässiga variabler förlorar alltså redan sin slumpmässiga karaktär och kan förutsägas med stor noggrannhet. Detta kan förklaras av det faktum att slumpmässiga avvikelser av värdena X i från a i kan ha olika tecken, och därför kompenseras dessa avvikelser totalt sett med stor sannolikhet.
Terema Chebysheva (lag om stora tal i form av Chebyshev). Låta X 1 , X 2 , … , X n … är en sekvens av parvis oberoende slumpvariabler vars varianser är begränsade till samma antal. Sedan, oavsett hur litet antalet ε vi tar, är sannolikheten för ojämlikhet
kommer att vara godtyckligt nära enhet om antalet n slumpvariabler att ta tillräckligt stora. Formellt betyder detta att under satsens villkor
Denna typ av konvergens kallas konvergens i sannolikhet och betecknas med:
Således säger Chebyshev-satsen att om det finns ett tillräckligt stort antal oberoende slumpvariabler, kommer deras aritmetiska medelvärde i ett enda test nästan säkert att ta ett värde nära genomsnittet av deras matematiska förväntningar.
Oftast tillämpas Chebyshev-satsen i en situation där slumpvariabler X 1 , X 2 , … , X n … har samma fördelning (d.v.s. samma fördelningslag eller samma sannolikhetstäthet). I själva verket är detta bara ett stort antal instanser av samma slumpvariabel.
Följd(generaliserad Chebyshev ojämlikhet). Om oberoende slumpvariabler X 1 , X 2 , … , X n … har samma fördelning med matematiska förväntningar M(X i )= a och dispersioner D(X i )= D, då
 , dvs.
, dvs.  .
.
Beviset följer av den generaliserade Chebyshev ojämlikheten genom att gå till gränsen som n→∞ .
Vi noterar än en gång att de ovan skrivna likheterna inte garanterar att kvantitetens värde  tenderar att a på n→∞. Detta värde är fortfarande en slumpmässig variabel, och dess individuella värden kan vara ganska långt ifrån a. Men sannolikheten för sådant (långt ifrån a) värden med ökande n tenderar till 0.
tenderar att a på n→∞. Detta värde är fortfarande en slumpmässig variabel, och dess individuella värden kan vara ganska långt ifrån a. Men sannolikheten för sådant (långt ifrån a) värden med ökande n tenderar till 0.
Kommentar. Slutsatsen av följden är uppenbarligen giltig även i det mer allmänna fallet när de oberoende stokastiska variablerna X 1 , X 2 , … , X n … har en annan fördelning, men samma matematiska förväntningar (lika a) och varianserna begränsade i aggregatet. Detta gör det möjligt att förutsäga noggrannheten för att mäta en viss kvantitet, även om dessa mätningar görs av olika instrument.
Låt oss överväga mer i detalj tillämpningen av denna följd för mätning av kvantiteter. Låt oss använda någon enhet n mätningar av samma kvantitet, vars verkliga värde är a och vi vet inte. Resultaten av sådana mätningar X 1
, X 2
, … , X n kan skilja sig väsentligt från varandra (och från det verkliga värdet a) på grund av olika slumpmässiga faktorer (tryckfall, temperaturer, slumpmässiga vibrationer, etc.). Betrakta r.v. X- instrumentavläsning för en enstaka mätning av en kvantitet, samt en uppsättning r.v. X 1
, X 2
, … , X n- instrumentavläsning vid första, andra, ..., sista mätningen. Således var och en av kvantiteterna X 1
, X 2
, … , X n
det finns bara ett av fallen av r.v. X, och därför har de alla samma fördelning som r.v. X. Eftersom mätresultaten är oberoende av varandra kan r.v. X 1
, X 2
, … , X n kan anses vara oberoende. Om enheten inte ger ett systematiskt fel (till exempel noll är inte "nedslagen" på skalan, fjädern inte sträcks etc.), så kan vi anta att den matematiska förväntan M(X) = a, och därför M(X 1
) = ... = M(X n ) = a. Således är villkoren för ovanstående följd uppfyllda, och därför, som ett ungefärligt värde på kvantiteten a vi kan ta "implementeringen" av en slumpvariabel  i vårt experiment (som består av en serie av n mått), dvs.
i vårt experiment (som består av en serie av n mått), dvs.
 .
.
Med ett stort antal mätningar är den praktiskt taget pålitlig bra noggrannhet beräkningar med denna formel. Detta är skälet till den praktiska principen att, med ett stort antal mätningar, deras aritmetiska medelvärde praktiskt taget inte skiljer sig mycket från det verkliga värdet av den uppmätta storheten.
"Sampling" -metoden, som används ofta i matematisk statistik, är baserad på lagen om stora siffror, vilket gör det möjligt att erhålla dess objektiva egenskaper med acceptabel noggrannhet från ett relativt litet urval av värden för en slumpmässig variabel. Men detta kommer att diskuteras i nästa avsnitt.
Exempel. På en mätanordning som inte gör systematiska förvrängningar mäts en viss kvantitet a en gång (mottaget värde X 1
), och sedan 99 gånger till (värdena X 2
, … , X 100
). För det verkliga värdet av mätningen a ta först resultatet av den första mätningen  , och sedan det aritmetiska medelvärdet av alla mätningar
, och sedan det aritmetiska medelvärdet av alla mätningar  . Anordningens mätnoggrannhet är sådan att standardavvikelsen för mätningen σ inte är mer än 1 (eftersom spridningen D=σ
2
inte heller överstiger 1). För var och en av mätmetoderna, uppskatta sannolikheten att mätfelet inte överstiger 2.
. Anordningens mätnoggrannhet är sådan att standardavvikelsen för mätningen σ inte är mer än 1 (eftersom spridningen D=σ
2
inte heller överstiger 1). För var och en av mätmetoderna, uppskatta sannolikheten att mätfelet inte överstiger 2.
Lösning. Låt r.v. X- instrumentavläsning för en enda mätning. Sedan efter villkor M(X)=a. För att besvara de ställda frågorna tillämpar vi den generaliserade Chebyshev-ojämlikheten

för ε =2
först för n=1
och sedan för n=100
. I det första fallet får vi  , och i den andra. Således garanterar det andra fallet praktiskt taget den givna mätnoggrannheten, medan det första lämnar allvarliga tvivel i denna mening.
, och i den andra. Således garanterar det andra fallet praktiskt taget den givna mätnoggrannheten, medan det första lämnar allvarliga tvivel i denna mening.
Låt oss tillämpa ovanstående påståenden på de slumpvariabler som uppstår i Bernoulli-schemat. Låt oss komma ihåg kärnan i detta schema. Låt det produceras n oberoende tester, i varje enskilt fall MEN kan dyka upp med samma sannolikhet R, a q=1–r(med betydelsen är detta sannolikheten för den motsatta händelsen - inte förekomsten av en händelse MEN) . Låt oss spendera ett antal n sådana tester. Tänk på slumpvariabler: X 1 – antal händelser av händelsen MEN i 1 provet, ..., X n– antal händelser av händelsen MEN i n det testet. Alla introducerade r.v. kan ta värderingar 0 eller 1 (händelse MEN kan visas i testet eller inte), och värdet 1 villkorligt accepterat i varje försök med en sannolikhet sid(sannolikheten att en händelse inträffar MEN i varje test) och värdet 0 med sannolikhet q= 1 – sid. Därför har dessa kvantiteter samma distributionslagar:
|
X 1 | ||
|
X n | ||
Därför är medelvärdena för dessa kvantiteter och deras dispersioner också desamma: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= sid ; D(X 1 )=(0 2 ∙ q+1 2 ∙ sid)− sid 2 = sid∙(1− sid)= sid ∙ q, …, D(X n )= sid ∙ q. Genom att ersätta dessa värderingar med den generaliserade Chebyshev-ojämlikheten får vi
 .
.
Det är uppenbart att r.v. X=X 1 +…+X när antalet händelser av händelsen MEN i alla n försök (som de säger - "antalet framgångar" i n tester). Släpp in n testhändelse MEN framträdde i k av dem. Då kan den tidigare ojämlikheten skrivas som
 .
.
Men storleken  , lika med förhållandet mellan antalet händelser av händelsen MEN i n oberoende försök, till det totala antalet försök, tidigare kallat den relativa händelsefrekvensen MEN i n tester. Därför finns det en ojämlikhet
, lika med förhållandet mellan antalet händelser av händelsen MEN i n oberoende försök, till det totala antalet försök, tidigare kallat den relativa händelsefrekvensen MEN i n tester. Därför finns det en ojämlikhet
 .
.
Går nu till gränsen kl n→∞, vi får  , dvs.
, dvs.  (enligt sannolikhet). Detta är innehållet i lagen om stora tal i form av Bernoulli. Av detta följer att för ett tillräckligt stort antal försök n godtyckligt små avvikelser av den relativa frekvensen
(enligt sannolikhet). Detta är innehållet i lagen om stora tal i form av Bernoulli. Av detta följer att för ett tillräckligt stort antal försök n godtyckligt små avvikelser av den relativa frekvensen  händelser från dess sannolikhet Rär nästan säkra händelser, och stora avvikelser är nästan omöjliga. Den resulterande slutsatsen om sådan stabilitet hos relativa frekvenser (som vi tidigare kallade experimentell faktum) motiverar den tidigare införda statistiska definitionen av sannolikheten för en händelse som ett tal kring vilket den relativa frekvensen av en händelse fluktuerar.
händelser från dess sannolikhet Rär nästan säkra händelser, och stora avvikelser är nästan omöjliga. Den resulterande slutsatsen om sådan stabilitet hos relativa frekvenser (som vi tidigare kallade experimentell faktum) motiverar den tidigare införda statistiska definitionen av sannolikheten för en händelse som ett tal kring vilket den relativa frekvensen av en händelse fluktuerar.
Med tanke på att uttrycket sid∙
q=
sid∙(1−
sid)=
sid−
sid 2
inte överskrider ändringsintervallet  (det är lätt att verifiera detta genom att hitta minimum av denna funktion på detta segment), från ovanstående ojämlikhet
(det är lätt att verifiera detta genom att hitta minimum av denna funktion på detta segment), från ovanstående ojämlikhet  lätt att få till det
lätt att få till det
 ,
,
som används för att lösa motsvarande problem (ett av dem kommer att ges nedan).
Exempel. Myntet vändes 1000 gånger. Uppskatta sannolikheten för att avvikelsen mellan den relativa frekvensen av vapnets utseende från dess sannolikhet kommer att vara mindre än 0,1.
Lösning. Att tillämpa ojämlikheten  på sid=
q=1/2
,
n=1000
,
e=0,1, vi får .
på sid=
q=1/2
,
n=1000
,
e=0,1, vi får .
Exempel. Uppskatta sannolikheten för att talet, under villkoren i föregående exempel k av de tappade vapensköldarna kommer att ligga inom intervallet 400 innan 600 .
Lösning. Skick 400<
k<600
innebär att 400/1000<
k/
n<600/1000
, dvs. 0.4<
W n (A)<0.6
eller  . Som vi just har sett från föregående exempel är sannolikheten för en sådan händelse minst 0.975
.
. Som vi just har sett från föregående exempel är sannolikheten för en sådan händelse minst 0.975
.
Exempel. För att beräkna sannolikheten för någon händelse MEN 1000 experiment genomfördes, där evenemanget MEN dykt upp 300 gånger. Uppskatta sannolikheten att den relativa frekvensen (lika med 300/1000=0,3) skiljer sig från den sanna sannolikheten R inte längre än 0,1.
Lösning. Att tillämpa ovanstående ojämlikhet  för n=1000, ε=0,1 får vi .
för n=1000, ε=0,1 får vi .
Lagen om stora siffror
Lagen om stora tal i sannolikhetsteorin anger att det empiriska medelvärdet (arithmetiskt medelvärde) av ett tillräckligt stort ändligt urval från en fast fördelning ligger nära det teoretiska medelvärdet (förväntningen) av denna fördelning. Beroende på typen av konvergens urskiljs en svag lag för stora tal, när konvergens i sannolikhet äger rum, och en förstärkt lag för stora tal, när konvergens nästan överallt äger rum.
Det kommer alltid att finnas ett sådant antal försök att, med vilken som helst förutbestämd sannolikhet, den relativa frekvensen av förekomst av någon händelse kommer att skilja sig godtyckligt lite från dess sannolikhet.
Den allmänna innebörden av lagen om stora siffror är att den gemensamma verkan av ett stort antal slumpmässiga faktorer leder till ett resultat som är nästan oberoende av slumpen.
Metoder för att uppskatta sannolikhet baserat på analys av ett ändligt urval baseras på denna egenskap. Ett bra exempel är förutsägelse av valresultat baserat på en undersökning av ett urval av väljare.
Svag lag av stora tal
Låt det finnas en oändlig sekvens (konsekutiv uppräkning) av identiskt fördelade och okorrelerade slumpvariabler , definierade på samma sannolikhetsutrymme . Det vill säga deras samvariation. Låt . Låt oss beteckna exempelmedelvärdet för de första termerna:
Stark lag om stora tal
Låt det finnas en oändlig sekvens av oberoende identiskt fördelade slumpvariabler, definierade på samma sannolikhetsutrymme. Låt . Låt oss beteckna exempelmedelvärdet för de första termerna:
.Då nästan säkert.
se även
Litteratur
- Shiryaev A.N. Sannolikhet, - M .: Vetenskap. 1989.
- Chistyakov V.P. Sannolikhetslära kurs, - M., 1982.
Wikimedia Foundation. 2010 .
- Cinema i Ryssland
- Gromeka, Mikhail Stepanovich
Se vad "Law of Large Numbers" är i andra ordböcker:
LAGEN OM STORA TAL- (lag om stora siffror) I fallet när beteendet hos enskilda medlemmar av befolkningen är mycket distinkt, är gruppens beteende i genomsnitt mer förutsägbart än beteendet hos någon av dess medlemmar. Trenden i vilka grupper ... ... Ekonomisk ordbok
LAGEN OM STORA TAL- se LAG FÖR STORA TAL. Antinazi. Encyclopedia of Sociology, 2009 ... Encyclopedia of Sociology
Lagen om stora siffror- principen enligt vilken de kvantitativa mönstren som är inneboende i sociala massfenomen tydligast manifesteras med ett tillräckligt stort antal observationer. Enstaka fenomen är mer mottagliga för effekterna av slumpmässiga och ... ... Ordlista över affärstermer
LAGEN OM STORA TAL- hävdar att med en sannolikhet nära ett, kommer det aritmetiska medelvärdet av ett stort antal slumpvariabler av ungefär samma ordning att skilja sig lite från en konstant lika med det aritmetiska medelvärdet av de matematiska förväntningarna på dessa variabler. Skillnad … … Geologisk uppslagsverk
lag om stora tal- — [Ya.N. Luginsky, M.S. Fezi Zhilinskaya, Yu.S. Kabirov. English Russian Dictionary of Electrical Engineering and Power Engineering, Moskva, 1999] Elektroteknikämnen, grundläggande begrepp EN lag om medelslag av stora tal ... Teknisk översättarhandbok
lag om stora tal- didžiųjų skaičių dėsnis statusas T sritis fizika atitikmenys: engl. lag om stora tal vok. Gesetz der großen Zahlen, n rus. lag om stora tal, m pranc. loi des grands nombres, f … Fizikos terminų žodynas
LAGEN OM STORA TAL- en allmän princip, på grund av vilken den kombinerade verkan av slumpmässiga faktorer leder, under vissa mycket allmänna förhållanden, till ett resultat som är nästan oberoende av slumpen. Konvergensen av frekvensen av förekomsten av en slumpmässig händelse med dess sannolikhet med en ökning av antalet ... ... Ryska sociologiska uppslagsverk
Lagen om stora siffror- lagen som anger att den kumulativa verkan av ett stort antal slumpmässiga faktorer under vissa mycket allmänna förhållanden leder till ett resultat nästan oberoende av slumpen ... Sociologi: en ordbok
LAGEN OM STORA TAL- Statistisk lag som uttrycker förhållandet mellan statistiska indikatorer (parametrar) för urvalet och den allmänna befolkningen. De faktiska värdena för statistiska indikatorer som erhålls från ett visst urval skiljer sig alltid från de så kallade. teoretiska ... ... Sociologi: Encyclopedia
LAGEN OM STORA TAL- principen att frekvensen av ekonomiska förluster av en viss typ kan förutsägas med hög noggrannhet när det finns ett stort antal förluster av liknande slag ... Encyclopedic Dictionary of Economics and Law
Böcker
- En uppsättning bord. Matte. Sannolikhetsteori och matematisk statistik. 6 tabeller + metodik, . Borden är tryckta på tjock polygrafisk kartong i måtten 680 x 980 mm. Satsen innehåller en broschyr med metodologiska rekommendationer för lärare. Pedagogiskt album med 6 ark. Slumpmässig…
Vad är hemligheten bakom framgångsrika säljare? Om du tittar på de bästa säljarna i något företag kommer du att märka att de har en sak gemensamt. Var och en av dem träffar fler människor och gör fler presentationer än de mindre framgångsrika säljarna. Dessa människor förstår att försäljning är ett sifferspel, och ju fler människor de berättar om sina produkter eller tjänster, desto fler affärer stänger de – det är allt. De förstår att om de kommunicerar inte bara med de få som definitivt säger ja till dem, utan också med dem vars intresse för deras förslag inte är så stort, så kommer lagen om medelvärden att fungera till deras fördel.
Dina intäkter kommer att bero på antalet försäljningar, men samtidigt kommer de att vara direkt proportionella mot antalet presentationer du gör. När du väl förstår och börjar omsätta lagen om medelvärden i praktiken, kommer oron förknippad med att starta ett nytt företag eller arbeta inom ett nytt område att börja minska. Och som ett resultat kommer en känsla av kontroll och förtroende för deras förmåga att tjäna att börja växa. Om du bara gör presentationer och finslipar dina kunskaper i processen kommer det att finnas erbjudanden.
Istället för att tänka på antalet erbjudanden, tänk på antalet presentationer. Det är ingen mening att vakna på morgonen eller komma hem på kvällen och börja undra vem som ska köpa din produkt. Istället är det bäst att planera varje dag för hur många samtal du behöver ringa. Och sedan, oavsett vad - ring alla dessa samtal! Detta tillvägagångssätt kommer att göra ditt jobb lättare - eftersom det är ett enkelt och specifikt mål. Om du vet att du har ett mycket specifikt och uppnåeligt mål framför dig blir det lättare för dig att göra det planerade antalet samtal. Om du hör "ja" ett par gånger under denna process, så mycket bättre!
Och om "nej", så kommer du på kvällen att känna att du ärligt gjorde allt du kunde, och du kommer inte att plågas av tankar om hur mycket pengar du har tjänat, eller hur många partners du har skaffat på en dag.
Låt oss säga att i ditt företag eller din verksamhet stänger en genomsnittlig säljare en affär var fjärde presentation. Föreställ dig nu att du drar kort från en kortlek. Varje kort med tre färger - spader, ruter och klöver - är en presentation där du professionellt presenterar en produkt, tjänst eller möjlighet. Du gör det så gott du kan, men du avslutar fortfarande inte affären. Och varje hjärtkort är en affär som låter dig få pengar eller skaffa en ny följeslagare.
Skulle du i en sådan situation inte vilja dra så många kort från leken som möjligt? Anta att du erbjuds att dra så många kort du vill, samtidigt som du betalar eller föreslår en ny följeslagare varje gång du drar ett hjärtkort. Du kommer att börja dra kort entusiastiskt, knappt märker vilken färg kortet just har dragits ut.
Du vet att det finns tretton hjärtan i en kortlek med femtiotvå kort. Och i två kortlekar - tjugosex hjärtkort och så vidare. Kommer du att bli besviken på att dra spader, ruter eller klöver? Självklart inte! Du kommer bara att tro att varje sådan "miss" för dig närmare - till vad? Till hjärternas kort!
Men vet du vad? Du har redan fått det här erbjudandet. Du är i en unik position att tjäna så mycket du vill och dra så många hjärtkort som du vill dra i ditt liv. Och om du bara "drar kort" samvetsgrant, förbättrar dina färdigheter och uthärdar lite spader, ruter och klubba, då kommer du att bli en utmärkt säljare och lyckas.
En av de saker som gör det så roligt att sälja är att varje gång du blandar kortleken blandas korten annorlunda. Ibland hamnar alla hjärtan i början av kortleken, och efter en lyckad rad (när det redan verkar för oss att vi aldrig kommer att förlora!) väntar vi på en lång rad kort i en annan färg. Och en annan gång, för att komma till första hjärtat, måste du gå igenom ett oändligt antal spader, klöver och tamburiner. Och ibland faller kort av olika färger ut strikt i tur och ordning. Men i alla fall, i varje kortlek med femtiotvå kort, i någon ordning, finns det alltid tretton hjärtan. Dra bara ut korten tills du hittar dem.
Från: Leylya,
Lagen om stora tal i sannolikhetsteorin anger att det empiriska medelvärdet (arithmetiskt medelvärde) av ett tillräckligt stort ändligt urval från en fast fördelning ligger nära det teoretiska medelvärdet (förväntningen) av denna fördelning. Beroende på typen av konvergens skiljer man mellan den svaga lagen för stora tal, när det finns konvergens i sannolikhet, och den starka lagen för stora tal, när det finns konvergens nästan överallt.
Det finns alltid ett ändligt antal försök för vilka, med en given sannolikhet, mindre än 1 den relativa frekvensen av att någon händelse inträffar kommer att skilja sig godtyckligt lite från dess sannolikhet.
Den allmänna innebörden av lagen om stora siffror: den gemensamma handlingen av ett stort antal identiska och oberoende slumpmässiga faktorer leder till ett resultat som i gränsen inte beror på slumpen.
Metoder för att uppskatta sannolikhet baserat på analys av ett ändligt urval baseras på denna egenskap. Ett bra exempel är förutsägelse av valresultat baserat på en undersökning av ett urval av väljare.
Encyklopedisk YouTube
1 / 5
✪ Lagen om stora tal
✪ 07 - Sannolikhetsteori. Lagen om stora siffror
✪ 42 lagen om stora tal
✪ 1 - Chebyshevs lag om stora tal
✪ Årskurs 11, lektion 25, Gaussisk kurva. Lagen om stora siffror
undertexter
Låt oss ta en titt på lagen om stora tal, som kanske är den mest intuitiva lagen inom matematik och sannolikhetsteori. Och eftersom det gäller så många saker används det ibland och missförstås. Låt mig först ge det en definition för noggrannhet, och sedan ska vi prata om intuition. Låt oss ta en slumpvariabel, säg X. Låt oss säga att vi vet dess matematiska förväntan eller populationsmedelvärde. Lagen om stora siffror säger helt enkelt att om vi tar exemplet med n:te antalet observationer av en slumpvariabel och genomsnittet av antalet av alla dessa observationer... Låt oss ta en variabel. Låt oss kalla det X med ett nedsänkt n och ett streck överst. Detta är det aritmetiska medelvärdet av det n:te antalet observationer av vår slumpvariabel. Här är min första observation. Jag gör experimentet en gång och jag gör den här observationen, sedan gör jag det igen och jag gör den här observationen, jag gör det igen och jag får det här. Jag kör detta experiment n gånger och dividerar sedan med antalet av mina observationer. Här är mitt provmedelvärde. Här är genomsnittet av alla observationer jag gjort. Lagen om stora tal säger oss att mitt urvalsmedelvärde kommer att närma sig medelvärdet av den slumpmässiga variabeln. Eller så kan jag också skriva att mitt urvalsmedelvärde kommer att närma sig populationsmedelvärdet för det n:e talet som går till oändlighet. Jag ska inte göra någon tydlig skillnad mellan "approximation" och "konvergens", men jag hoppas att du intuitivt förstår att om jag tar ett ganska stort urval här, så får jag det förväntade värdet för populationen som helhet. Jag tror att de flesta av er intuitivt förstår att om jag gör tillräckligt många tester med ett stort urval av exempel, så kommer testerna så småningom att ge mig de värden jag förväntar mig, med hänsyn till den matematiska förväntningen, sannolikheten och allt det där. Men jag tror att det ofta är oklart varför detta händer. Och innan jag börjar förklara varför det är så, låt mig ge dig ett konkret exempel. Lagen om stora tal säger oss att... Låt oss säga att vi har en slumpvariabel X. Den är lika med antalet huvuden i 100 kast av rätt mynt. Först och främst känner vi till den matematiska förväntan av denna slumpvariabel. Detta är antalet myntkast eller utmaningar multiplicerat med oddsen för att någon utmaning ska lyckas. Så det är lika med 50. Det vill säga lagen om stora siffror säger att om vi tar ett prov, eller om jag snittar dessa försök, så får jag. .. Första gången jag gör ett test slår jag ett mynt 100 gånger, eller tar en låda med hundra mynt, skakar den och räknar sedan hur många huvuden jag får, och får, säg, siffran 55. Det här blir X1. Sedan skakar jag lådan igen och jag får siffran 65. Sedan igen - och jag får 45. Och jag gör detta n gånger, och sedan dividerar jag det med antalet försök. Lagen om stora tal säger oss att detta medelvärde (genomsnittet av alla mina observationer) kommer att tendera till 50 medan n kommer att tendera till oändligheten. Nu skulle jag vilja prata lite om varför detta händer. Många menar att om mitt resultat efter 100 försök ligger över medel, så borde jag enligt sannolikhetslagarna ha mer eller mindre huvuden för att så att säga kompensera för skillnaden. Detta är inte exakt vad som kommer att hända. Detta kallas ofta för "gamblers felslut". Låt mig visa dig skillnaden. Jag kommer att använda följande exempel. Låt mig rita en graf. Låt oss ändra färgen. Det här är n, min x-axel är n. Det här är antalet tester jag kommer att köra. Och min y-axel kommer att vara provmedelvärdet. Vi vet att medelvärdet för denna godtyckliga variabel är 50. Låt mig rita det här. Det här är 50. Låt oss gå tillbaka till vårt exempel. Om n är... Under mitt första test fick jag 55, vilket är mitt snitt. Jag har bara en datainmatningspunkt. Sedan, efter två försök, får jag 65. Så mitt snitt skulle vara 65+55 dividerat med 2. Det är 60. Och mitt snitt gick upp lite. Sedan fick jag 45, vilket sänkte mitt aritmetiska medelvärde igen. Jag kommer inte att rita 45 i diagrammet. Nu måste jag räkna ut det hela. Vad är 45+65 lika med? Låt mig beräkna detta värde för att representera punkten. Det är 165 dividerat med 3. Det är 53. Nej, 55. Så genomsnittet går ner till 55 igen. Vi kan fortsätta dessa tester. Efter att vi gjort tre försök och kommit fram till detta snitt tror många att sannolikhetens gudar kommer att göra så att vi får färre huvuden i framtiden, att de kommande försöken blir lägre för att sänka snittet. Men det är inte alltid så. I framtiden förblir sannolikheten alltid densamma. Sannolikheten att jag kommer att rulla huvuden kommer alltid att vara 50%. Inte för att jag till en början får ett visst antal huvuden, fler än jag förväntar mig, och så ska det plötsligt falla ut svansar. Detta är "spelarens felslut". Om du får oproportionerligt många huvuden betyder det inte att du någon gång kommer att börja ramla ut oproportionerligt många svansar. Detta är inte helt sant. Lagen om stora tal säger oss att det inte spelar någon roll. Låt oss säga att efter ett visst ändligt antal försök, ditt medelvärde... Sannolikheten för detta är ganska liten, men ändå... Låt oss säga att ditt medelvärde når detta märke - 70. Du tänker, "Wow, vi har gått långt över förväntan." Men lagen om stora siffror säger att det inte bryr sig om hur många tester vi kör. Vi har fortfarande ett oändligt antal prövningar framför oss. De matematiska förväntningarna på detta oändliga antal försök, särskilt i en situation som denna, kommer att vara följande. När du kommer till ett ändligt tal som uttrycker något stort värde, kommer ett oändligt tal som konvergerar med det igen att leda till det förväntade värdet. Detta är förstås en väldigt lös tolkning, men detta är vad lagen om stora tal säger oss. Det är viktigt. Han säger inte till oss att om vi får många huvuden, så kommer på något sätt oddsen att få svansar att öka för att kompensera. Denna lag säger oss att det inte spelar någon roll vad resultatet blir med ett ändligt antal prövningar så länge du fortfarande har ett oändligt antal prövningar framför dig. Och om du gör tillräckligt mycket av dem, kommer du att vara tillbaka till förväntan igen. Detta är en viktig punkt. Tänk på det. Men detta används inte dagligen i praktiken med lotterier och kasinon, även om man vet att om man gör tillräckligt många tester... Vi kan till och med räkna ut det... vad är sannolikheten att vi på allvar kommer att avvika från normen? Men kasinon och lotterier arbetar varje dag efter principen att om du tar tillräckligt många människor, naturligtvis, på kort tid, med ett litet urval, så kommer ett fåtal personer att slå jackpotten. Men på lång sikt kommer casinot alltid att dra nytta av parametrarna för de spel de bjuder in dig att spela. Detta är en viktig sannolikhetsprincip som är intuitiv. Även om det ibland, när det förklaras formellt för dig med slumpvariabler, ser lite förvirrande ut. Allt som denna lag säger är att ju fler sampel det finns, desto mer kommer det aritmetiska medelvärdet av dessa sampel att konvergera mot det sanna medelvärdet. Och för att vara mer specifik kommer det aritmetiska medelvärdet av ditt urval att konvergera med den matematiska förväntan av en slumpvariabel. Det är allt. Vi ses i nästa video!
Svag lag av stora tal
Den svaga lagen om stora tal kallas också för Bernoullis sats, efter Jacob Bernoulli, som bevisade den 1713.
Låt det finnas en oändlig sekvens (konsekutiv uppräkning) av identiskt fördelade och okorrelerade slumpvariabler . Det vill säga deras samvariation c o v (X i, X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). Låt . Beteckna med stickprovets medelvärde för den första n (\displaystyle n) medlemmar:
.
Sedan X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
Det vill säga för varje positivt ε (\displaystyle \varepsilon )
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Stark lag om stora tal
Låt det finnas en oändlig sekvens av oberoende identiskt fördelade slumpvariabler ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty )) definieras på ett sannolikhetsutrymme (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F)),\mathbb (P))). Låta E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N) ). Beteckna med X¯n (\displaystyle (\bar(X))_(n)) provmedelvärde för den första n (\displaystyle n) medlemmar:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\summa \limits _(i= 1)^(n)X_(i),\;n\i \mathbb (N) ).Sedan X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu ) nästan alltid.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ höger)=1.) .Liksom alla matematiska lagar kan lagen om stora tal endast tillämpas på den verkliga världen under kända antaganden, som bara kan uppfyllas med en viss grad av noggrannhet. Så till exempel kan villkoren för successiva tester ofta inte upprätthållas på obestämd tid och med absolut noggrannhet. Dessutom talar lagen om stora tal bara om osannolikhet betydande avvikelse av medelvärdet från den matematiska förväntan.
Medelvärdet är den mest generella indikatorn i statistik. Detta beror på att det kan användas för att karakterisera populationen efter ett kvantitativt varierande attribut. Till exempel, för att jämföra lönerna för arbetare i två företag, kan lönerna för två specifika arbetare inte tas, eftersom det fungerar som en varierande indikator. Dessutom kan det totala beloppet för löner som betalas i företag inte tas, eftersom det beror på antalet anställda. Om vi dividerar de totala lönerna för varje företag med antalet anställda kan vi jämföra dem och avgöra vilket företag som har en högre medellön.
Med andra ord får lönerna för den studerade befolkningen av arbetare en generaliserad egenskap i medelvärdet. Den uttrycker det allmänna och typiska som är kännetecknande för helheten av arbetare i förhållande till den egenskap som studeras. I detta värde visar det det allmänna måttet för denna funktion, som har ett annat värde för befolkningens enheter.
Bestämning av medelvärdet. Ett medelvärde i statistik är en generaliserad egenskap hos en uppsättning fenomen av samma typ enligt något kvantitativt varierande attribut. Medelvärdet visar nivån på denna funktion, relaterad till befolkningsenheten. Med hjälp av medelvärdet är det möjligt att jämföra olika aggregat med varandra enligt olika egenskaper (inkomst per capita, skörd, produktionskostnader vid olika företag).
Medelvärdet generaliserar alltid den kvantitativa variationen av egenskapen som vi karakteriserar populationen som studeras, och som är lika inneboende i alla enheter i befolkningen. Det betyder att det bakom varje medelvärde alltid finns en serie av fördelning av befolkningens enheter enligt något varierande attribut, d.v.s. variationsserie. I detta avseende skiljer sig medelvärdet fundamentalt från relativa värden och i synnerhet från intensitetsindikatorer. Intensitetsindikatorn är förhållandet mellan volymerna av två olika aggregat (till exempel produktionen av BNP per capita), medan den genomsnittliga generaliserar egenskaperna hos elementen i aggregatet enligt en av egenskaperna (till exempel genomsnittet lön för en arbetare).
Medelvärde och de stora talens lag. I förändringen av genomsnittliga indikatorer manifesteras en allmän trend, under påverkan av vilken utvecklingsprocessen av fenomen som helhet bildas, medan denna trend i enskilda enskilda fall kanske inte manifesteras tydligt. Det är viktigt att genomsnitten baseras på en massiv generalisering av fakta. Endast under detta villkor kommer de att avslöja den allmänna trenden som ligger bakom processen som helhet.
Kärnan i lagen om stora tal och dess betydelse för medelvärden, när antalet observationer ökar, blir mer och mer komplett. Det vill säga lagen om stora siffror skapar förutsättningar för att en typisk nivå av ett variabelt drag ska dyka upp i medelvärdet under specifika förhållanden av plats och tid. Värdet på denna nivå bestäms av essensen av detta fenomen.
Typer av medelvärden. Medelvärden som används i statistik tillhör klassen av kraftmedel, vars allmänna formel är följande:
Där x är potensmedelvärdet;
X - ändra värden för attributet (alternativ)
- nummeralternativ
Medelvärdets exponent;
Summering tecken.
För olika värden på medelvärdets exponent erhålls olika typer av medelvärdet:
Aritmetiskt medelvärde;
Genomsnittlig kvadrat;
Genomsnittlig kubik;
Genomsnittlig harmonisk;
Geometriskt medelvärde.
Olika typer av medelvärden har olika innebörd när man använder samma källstatistik. Samtidigt, ju större exponent för medelvärdet är, desto högre är dess värde.
I statistiken ger endast en väldefinierad typ av medelvärden en korrekt karakterisering av befolkningen i varje enskilt fall. För att bestämma denna typ av medelvärde används ett kriterium som bestämmer medelvärdets egenskaper: medelvärdet kommer först då att vara en sann generaliserande egenskap hos populationen enligt det varierande attributet, när, när alla varianter ersätts med medelvärdet. värde förblir den totala volymen av det varierande attributet oförändrad. Det vill säga att den korrekta typen av medelvärde bestäms av hur den totala volymen av den variabla egenskapen bildas. Således används det aritmetiska medelvärdet när volymen av det variabla särdraget bildas som summan av individuella alternativ, medelkvadraten - när volymen av det variabla elementet bildas som summan av kvadrater, det harmoniska medelvärdet - som summan av de ömsesidiga värdena för de individuella alternativen, det geometriska medelvärdet - som produkten av individuella alternativ. Förutom medelvärden i statistik
De beskrivande egenskaperna för fördelningen av en variabel egenskap (strukturella medelvärden), mode (den vanligaste varianten) och median (mellanvarianten) används.



